User’s guide#
Introduction: Welcome to EmPy!#
EmPy is a powerful, robust and mature
templating system for inserting Python code in template text. EmPy
takes a source document, processes it, and produces output. This is
accomplished via expansions, which are signals to the EmPy system
where to act and are indicated with markup. Markup is set off by a
customizable prefix (by default the at sign, @). EmPy can expand
arbitrary Python expressions, statements and control structures in
this way, as well as a variety of additional special forms. The
remaining textual data is sent to the output, allowing Python to be
used in effect as a markup language.
EmPy also supports hooks, which can intercept and modify the behavior of a running interpreter; diversions, which allow recording and playback; filters, which can alter output and can be chained together. The system is highly configurable via command line options, configuration files, and environment variables. EmPy documents can also be imported as modules, and an extensive API is also available for embedding EmPy functionality in your own Python programs.
EmPy also has a supplemental library for additional non-essential
features (emlib), a documentation building library used to create
this documentation (emdoc), and an extensive help system (emhelp)
which can be queried from the command line with the main executable
em.py (-h/--help, -H/--topics=TOPICS). The base EmPy
interpreter can function with only the em.py/em file/module
available.
EmPy can be used in a variety of roles, including as a templating system, a text processing system (preprocessing and/or postprocessing), a simple macro processor, a frontend for a content management system, annotating documents, for literate programming, as a souped-up text encoding converter, a text beautifier (with macros and filters), and many other purposes.
Markup overview#
Expressions are embedded in text with the @(...) notation;
variations include conditional expressions with @(...?...!...) and
the ability to handle thrown exceptions with @(...$...). As a
shortcut, simple variables and expressions can be abbreviated as
@variable, @object.attribute, @sequence[index],
@function(arguments...), and combinations. Functions can be called
with expanded markup as arguments using @function{markup}{...}.
Full-fledged statements are embedded with @{...}. Control flow in
terms of conditional or repeated expansion is available with
@[...]. A @ followed by any whitespace character (including a
newline) expands to nothing, allowing string concatenations and line
continuations. Line comments are indicated with @#... including
the trailing newline. @*...* allows inline comments. Output can
be disabled and re-enabled with @-... and @+..., including the
trailing newlines. Escapes are indicated with @\...; diacritics
with @^...; icons with @|...; and emoji with @:...:.
@%..., @%!..., @%%...%% and @%%!...%% indicate
“significators,” which are distinctive forms of variable assignment
intended to specify document metadata in a format easy to parse
externally. In-place expressions are specified with @$...$...$.
Context name and line number changes can be made with @?... and
@!..., respectively. A set of markups (@((...)), @[[...]],
@{{...}}, @<...>) are customizable by the user and can be used
for any desired purpose. @`...` allows literal escaping of any
EmPy markup. Output can be toggled on and off with @+ and @-,
respectively. And finally, a @@ sequence (the prefix repeated
once) expands to a single literal at sign.
The prefix defaults to @ but can be changed with
the command line option -p/--prefix=CHAR (environment variable: EMPY_PREFIX, configuration variable: prefix).
Getting the software#
The current version of EmPy is 4.2.1.
The official URL for this Web site is http://www.alcyone.com/software/empy/.
The latest version of the software is available in a tarball here:
http://www.alcyone.com/software/empy/empy-latest.tar.gz.
The software can be installed through PIP via this shell command:
% python3 -m pip install empy
For information about upgrading from 3.x to 4.x, see
http://www.alcyone.com/software/empy/ANNOUNCE.html#changes.
Requirements#
EmPy works with any modern version of Python. Python version 3.x is
expected to be the default and all source file references to the
Python interpreter (e.g., the bangpath of the .py scripts) use
python3. EmPy also has legacy support for versions of Python going
back all the way to 2.4, with special emphasis on 2.7 regardless of
its end-of-life status. It has no dependency requirements on any
third-party modules and can run directly off of a stock Python
interpreter.
EmPy will run on any operating system with a full-featured Python interpreter; this includes, but is probably not limited to, the operating systems Linux, Windows, Windows Subsystem for Linux 2 (WSL2) and macOS (Darwin). Using EmPy requires knowledge of the Python language.
EmPy is compatible with many different Python implementations, interpreter variants, packaging systems, and enhanced shells:
Variant |
Supported versions |
Description |
|---|---|---|
2.4 and up |
Standard implementation in C |
|
2.7 and up |
Implementation with just-in-time compiler |
|
2.4 and up |
Implementation supporting microthreading |
|
2.7 and up |
Implementation for .NET CLR and Mono |
|
2.5 to 2.7 (and up?) |
Implementation for JVM |
|
2.7 and up |
Secure supply chain open source solution |
|
2.5 and up |
One-file, no-installation CPython environment |
|
3.0 and up |
Portable Scientific Python for Windows |
|
2.7 and up |
Minimalistic Python distribution for Windows |
|
all |
Python’s Integrated Development and Learning Environment |
|
all |
Powerful interactive shell; kernel for Jupyter |
EmPy is also compatible with scaled-down implementations of Python, provided they support the set of standard modules that EmPy requires, namely:
codecscopygetoptosplatformresysunicodedata
Only a few .py module file(s) are needed to use EmPy; they can be
installed system-wide through a distribution package, via PIP, or just
dropped into any desired directory in the PYTHONPATH (as a module)
and/or PATH (as an executable). A minimal installation need only
install the em.py file, either as an importable module or an
executable, or both, depending on the user’s needs.
EmPy also has optional support for several third-party emoji modules; see Emoji markup: @:...: for details.
The testing system included (the test.sh script and the tests and suites directories) is intended to run on Unix-like systems with a Bourne-like shell (e.g., sh, bash, zsh, etc.). EmPy is routinely tested with all supported versions of all available interpreters.
If you find an incompatibility with your Python interpreter or operating system, let me know.
License#
This software is licensed under BSD (3-Clause).
Getting started#
This section serves as a quick introduction to the EmPy system. For more details, see the sections below.
Hint
As an introduction to the terminology, the following names are used throughout:
Name |
Description |
|---|---|
|
The name of the software |
|
The name of the executable and main source file |
|
The name of the main module |
|
The name of the pseudomodule, as well as the PyPI package |
|
The conventional filename extension for EmPy documents |
Starting EmPy#
After installing EmPy (see Getting the software), EmPy is invoked
by running the EmPy executable, em.py, on the command line
(standalone mode). If it is invoked without arguments, it will accept
input from sys.stdin. Unless otherwise specified, the output is
sent to sys.stdout. You can use this as an interactive session to
familiarize yourself with EmPy when starting out:
% em.py ... accepts input from stdin with results written to stdout ...
If an EmPy document is specified (which by convention has the extension .em, though this is not enforced), then that document is used as input:
% em.py document.em ... document.em is processed with results written to stdout ...
Note
In some distribution packages, the EmPy interpreter may be named
empy rather than em.py. In the official release
tarballs, and throughout this documentation,
it is em.py. This is to distinguish it from the pseudomodule
empy.
Warning
If your document filename begins with a -, it will be interpreted as
a command line argument and cause command line option processing
errors. Either precede it with a relative path (e.g., em.py ./-weirdname.em) or the GNU-style -- option which indicates there
are no further options (e.g., em.py -- -weirdname.em).
Any number of command line arguments (beginning with - or --) can
precede the document name. The command line argument -- indicates
that there are no more options. For instance, this command writes its
output to document.out:
% em.py -o document.out document.em ... document.em is processed with results written to document.out ...
Many options are available to change the behavior of the EmPy system. This command will open the input file as UTF-8, write the output file as Latin-1, show raw errors if they occur, and delete the output file if an error occurs:
% em.py --input-encoding=utf-8 --output-encoding=latin-1 -r -d -o document.out document.em ... you get the idea ...
EmPy documents can also take arguments, which are an arbitrary
sequence of strings that follow after the document, and are analogous
to the Python interpreter arguments sys.argv:
% em.py document.em run test ... empy.argv is ['document.em', 'run', 'test'] ...
Tip
When installed as a module, EmPy can also be invoked as
% python3 -m em ...
Tip
You can create executable EmPy scripts by making their file executable and starting them with a bangpath:
#!/usr/bin/env em.py
... EmPy code here ...
By default, bangpaths are treated as EmPy comments unless
--no-ignore-bangpaths (configuration variable: ignoreBangpaths = False) is specified.
Tip
If you wish to run EmPy under Python 2.x for some reason on a system
that also has Python 3 installed, explicitly invoke the Python 2
interpreter when running it (python2 em.py ...). If you wish to
make this more streamlined, edit the first line (“bangpath”) of the
em.py executable and change it to read #!/usr/bin/env python2 (or
whatever your Python 2.x interpreter is named).
See also
See the Command line options section for a list of command line options that EmPy supports.
The prefix and markup expansion#
EmPy markup is indicated with a configurable prefix, which is
by default the at sign (@). The character (Unicode code point)
following the prefix indicates what type of markup it is. There are a
wide variety of markups available, from comments to expression
evaluation to statement execution, and from prefixes, literals and
escapes to diacritics, icons and emojis. Converting markup into text
to be rendered as output is referred to as expansion. Here is a
long EmPy code sample illustrating some of the more essential markups
in EmPy, though there are several not shown here:
Example 1: Markup sample
Source: ⌨️
Comments:
The line below will not render.
@# This is a line comment, up to and including the newline.
If a line comment appears in the middle of a line, @# this is a comment!
the line will be continued.
Inline comments can be @*placed inline* (this phrase did not render,
but note the double space due to the spaces before and after it).
@**
* Or it can span multiple lines.
**@
Whitespace markup consumes the following space.
So two@ words become one word.
And this @
is a line continuation.
@* Inline comments can be used as a line comment. *@
Note the use of the trailing prefix to consume the final newline; this
is a common idiom.
Literals:
Double the prefix to render it: @@.
String literals can be used to render escaped Python strings: @
@"A is also \N{LATIN CAPITAL LETTER A}".
Escape markup can render arbitrary characters:
These are all Latin capital letter A: @
A, @\B{1000001}, @\q1001, @\o101, @\x41, @\u0041, @\U00000041, @\N{LATIN CAPITAL LETTER A}.
Backquotes can be used to escape EmPy markup.
This is not evaluated: @`@(!@#$%^&*()`.
Expressions:
Python expressions can be evaluated like this: 1 + 2 = @(1 + 2).
Expressions can be arbitrary complex: @
This is running in Python @('.'.join(str(x) for x in __import__('sys').version_info[:3])).
Expressions can contain builtin ternary operators:
Seven is an @(7 % 2 == 0 ? 'even' ! 'odd') number.
They can even handle exceptions: @
Division by zero is @(1/0 $ 'illegal').
Statements:
@{
print("Hello, world!")
x = 123
}@
x is now @(x), which can be simplified to @x.
Statements can execute arbitrarily complex Python code,
including defining functions and classes.
Back to expressions, they can be simplified:
@{
# Define some variables.
class Person:
def __init__(self, name):
self.name = name
a = [4, 5, 6]
p = Person('Fred')
}@
x is @x.
a[1] is @a[1].
The name of p is @p.name.
You can even call functions this way:
p's name when shouted is @p.name.upper().
Note that the parser does not try to evaluate end-of-sentence punctuation.
Control structures:
Iterate over some numbers and classify them, but stop after 5:
@[for n in range(-1, 10)]@
@[ if n > 5]@
And done.
@[ break]@
@[ end if]@
@n is @
@[ if n < 0]@
negative@
@[ elif n == 0]@
zero@
@[ elif n % 2 == 0]@
even@
@[ else # odd]@
odd@
@[ end if]@
.
@[end for]@
Note the use of indentation inside control markup and end-of-line
whitespace markup (a prefix with trailing whitespace is consumed) to
make things more clear (though this is optional).
You can even define your own EmPy functions:
@[def officer(name, species, rank, role)]@
@# The definition is EmPy, not Python!
@name (@species, @rank, @role)@
@[end def]@
Some of the bridge crew of the USS Enterprise (NCC-1701):
- @officer("James T. Kirk", "Human", "captain", "commanding officer")
- @officer("Spock", "Vulcan-Human hybrid", "commander", "science officer")
- @officer("Montgomery Scott", "Human", "commander", "chief engineer")
- @officer("Nyota Uhura", "Human", "lieutenant commander", "communications officer")
- @officer("Hikaru Sulu", "Human", "commander", "astrosciences/helmsman")
Diacritics: Libert@^e', @^e'galit@^e', fraternit@^e'!
Icons for curly quotes: @|"(these are curly quotes.@|")
This is an emoji: @:pile of poo:. (Of course I would choose that one.)
Output: 🖥️
Comments:
The line below will not render.
If a line comment appears in the middle of a line, the line will be continued.
Inline comments can be (this phrase did not render,
but note the double space due to the spaces before and after it).
Whitespace markup consumes the following space.
So twowords become one word.
And this is a line continuation.
Note the use of the trailing prefix to consume the final newline; this
is a common idiom.
Literals:
Double the prefix to render it: @.
String literals can be used to render escaped Python strings: A is also A.
Escape markup can render arbitrary characters:
These are all Latin capital letter A: A, A, A, A, A, A, A, A.
Backquotes can be used to escape EmPy markup.
This is not evaluated: @(!@#$%^&*().
Expressions:
Python expressions can be evaluated like this: 1 + 2 = 3.
Expressions can be arbitrary complex: This is running in Python 3.10.12.
Expressions can contain builtin ternary operators:
Seven is an odd number.
They can even handle exceptions: Division by zero is illegal.
Statements:
Hello, world!
x is now 123, which can be simplified to 123.
Statements can execute arbitrarily complex Python code,
including defining functions and classes.
Back to expressions, they can be simplified:
x is 123.
a[1] is 5.
The name of p is Fred.
You can even call functions this way:
p's name when shouted is FRED.
Note that the parser does not try to evaluate end-of-sentence punctuation.
Control structures:
Iterate over some numbers and classify them, but stop after 5:
-1 is negative.
0 is zero.
1 is odd.
2 is even.
3 is odd.
4 is even.
5 is odd.
And done.
Note the use of indentation inside control markup and end-of-line
whitespace markup (a prefix with trailing whitespace is consumed) to
make things more clear (though this is optional).
You can even define your own EmPy functions:
Some of the bridge crew of the USS Enterprise (NCC-1701):
- James T. Kirk (Human, captain, commanding officer)
- Spock (Vulcan-Human hybrid, commander, science officer)
- Montgomery Scott (Human, commander, chief engineer)
- Nyota Uhura (Human, lieutenant commander, communications officer)
- Hikaru Sulu (Human, commander, astrosciences/helmsman)
Diacritics: Liberté, égalité, fraternité!
Icons for curly quotes: “these are curly quotes.”
This is an emoji: 💩. (Of course I would choose that one.)
Tip
If you wish to change the prefix, use -p/--prefix=CHAR (environment variable: EMPY_PREFIX, configuration variable: prefix).
See also
See the Markup section for detailed specifications on all support EmPy markup.
Pseudomodule and interpreter#
The interpreter instance is available to a running EmPy system
through the globals; by default, it is named
empy. When it is referenced this way, it
is called a pseudomodule (since it acts like a module although it
is not actually a module you can import):
Example 2: Pseudomodule sample
Source: ⌨️
This version of EmPy is @empy.version.
The prefix in this interpreter is @empy.getPrefix() @
and the pseudomodule name is @empy.config.pseudomoduleName.
Do an explicit write: @empy.write("Hello, world!").
The context is currently @empy.getContext().
Adding a new global in a weird way: @
@empy.updateGlobals({'q': 789})@
Now q is @q!
You can do explicit expansions: @empy.expand("1 + 1 = @(1 + 1)").
q is @(empy.defined('q') ? 'defined' ! 'undefined').
Output: 🖥️
This version of EmPy is 4.2.1.
The prefix in this interpreter is @ and the pseudomodule name is empy.
Do an explicit write: Hello, world!.
The context is currently <example 2 "Pseudomodule sample">:5:26.
Adding a new global in a weird way: Now q is 789!
You can do explicit expansions: 1 + 1 = 2.
q is defined.
See also
See the Pseudomodule/interpreter section for details on the pseudomodule/interpreter.
Diversions, filters & hooks#
Diversions can defer and replay output at a desired time:
Example 3: Diversions sample
Source: ⌨️
This text is output normally.
@empy.startDiversion('A')@
(This text was diverted!)
@empy.stopDiverting()@
This text is back to being output normally.
Now playing the diversion:
@empy.playDiversion('A')@
And now back to normal output.
Output: 🖥️
This text is output normally.
This text is back to being output normally.
Now playing the diversion:
(This text was diverted!)
And now back to normal output.
Filters can modify output before sending it to the final stream:
Example 4: Filters sample
Source: ⌨️
@{
# For access to the filter classes.
import emlib
}@
This text is normal.
@empy.appendFilter(emlib.FunctionFilter(lambda x: x.upper()))@
This text is in all uppercase!
@empy.appendFilter(emlib.FunctionFilter(lambda x: '[' + x + ']'))@
Now it's also surrounded by brackets!
(Note the brackets are around output as it is sent,
not at the beginning and end of each line.)
@empy.resetFilter()@
Now it's back to normal.
Output: 🖥️
This text is normal.
THIS TEXT IS IN ALL UPPERCASE!
[NOW IT'S ALSO SURROUNDED BY BRACKETS!
(NOTE THE BRACKETS ARE AROUND OUTPUT AS IT IS SENT,
NOT AT THE BEGINNING AND END OF EACH LINE.)
]Now it's back to normal.
Hooks can intercept and even alter the behavior of a running system:
Example 5: Hooks sample
Source: ⌨️
@# Modify the backquote markup to prepend and append backquotes
@# (say, for a document rendering system, cough cough).
@{
import emlib
class BackquoteHook(emlib.Hook):
def __init__(self, interp):
self.interp = interp
def preBackquote(self, literal):
self.interp.write('`' + literal + '`')
return True # return true to skip the standard behavior
empy.addHook(BackquoteHook(empy))
}@
Now backquote markup will render with backquotes: @
@`this is now in backquotes`!
Output: 🖥️
Now backquote markup will render with backquotes: `this is now in backquotes`!
See also
See the Diversions, Filters, or the Hooks sections for more information.
Embedding#
EmPy is modular and can be embedded in your Python programmers,
rather than running it standalone. In Python, simply import the em
module and create an Interpreter:
import sys
import em
config = em.Configuration(...)
output = sys.stdout
with em.Interpreter(config=config, output=output) as interp:
... do things with interp ...
An exception which occurs during processing will be handled by the interpreter’s error handler.
For one-off uses, you can use the global, standalone expand function:
import em
result = em.expand(source)
When calling this function, an ephemeral interpreter is dynamically created, used, and shutdown to perform the expansion. If an exception occurs during this processing, it will be raised to the caller, rather than handled by the ephemeral interpreter.
Important
When you create an interpreter, you must call its shutdown method
when you are done. This is required to remove the proxy on
sys.stdout that EmPy requires for proper operation and restore your
Python environment to the state it was before creating the
interpreter. This can be accomplished by creating the interpreter in
a with statement — interpreters are also context managers — or by
creating it and shutting it down in a try/finally statement.
This is not needed when calling the expand global function; it
creates and shuts down an ephemeral interpreter automatically.
See also
See the Embedding EmPy section for more details on embedding EmPy in your Python programs.
Getting help#
For basic help, use the -h/--help option:
% em.py -h # or: --help Welcome to EmPy version 4.2.1. USAGE: ./em.py [<options>] [<filename, or `-` for stdin> [<argument>...]] - Options begin with `-` or `--` - Specify a filename (and arguments) to process that document as input - Specify `-` (and arguments) to process stdin with standard buffering - Specify no filename to enter interactive mode with line buffering - Specify `--` to stop processing options ...
For more help, repeat the -h/--help option (up to three times
for the full help). For help on a particular topic, use the
-H/--topics=TOPICS option, where TOPICS is a comma-separated list of
topics. The list of available topics can be shown by using the topic
topics:
% em.py -H topics # or: --topics=topics Welcome to EmPy version 4.2.1. TOPICS: Need more help? Add more -h options (-hh, -hhh) for more help. Use -H <topic> for help on a specific topic, or specify a comma-separated list of topics. Try `default` (-h) for default help, `more` (-hh) for more common topics, `all` (-hhh) for all help topics, or `topics` for this list. Use -V for version information, -W for version and system information, or -Z for all debug details. Available topics: usage Basic command line usage options Command line options simple Simple (one-letter) command line options markup Markup syntax escapes Escape sequences environ Environment variables pseudo Pseudomodule attributes and functions constructor Keyword arguments for the Interpreter constructor variables Configuration variable attributes methods Configuration methods hooks Hook methods named Named escapes diacritics Diacritic combiners icons Icons hints Usage hints topics This list of topics
Tip
Repeating the help option once (-hh) is the same as requesting the
more topic (-H more). Repeating it three times (-hhh) is the
same as requesting the all topic (-H all).
Warning
The builtin help system requires the presence of the emhelp module.
If you have a minimal EmPy installation, this module may not be
available. You can get it from the release
tarball.
See also
See the rest of this document for details and specifications on all the markup and features, and see the Help topics section for the output of all the builtin help topics.
Markup#
EmPy markup always begins with the EmPy prefix, which defaults to
@. The character (Unicode code point) following the prefix
indicates what type of markup it is, and the different types of markup
are parsed differently.
It is legal to set the EmPy prefix to None; then, no markup will be
parsed or expanded and EmPy will merely process filters and encoding
conversions. This can be done from the command line with the
--no-prefix option, or by indicating a prefix that is an
empty string ('') or the word none.
Using a non-default prefix that is also the first character of an
existing markup will swap that markup character with the default. For
example, setting the prefix to $ would otherwise collide with the
in-place token (@$...$...$ with a default prefix). On startup
it will be adjusted so that with a $ prefix the in-place markup can
be accessed as $@...@...@.
The following subsections list the types of markup supported by EmPy
and in which version they were introduced, organized by category.
NL represents a newline and WS represents any whitespace.
Important
All of the following code snippets and examples below assume that the
prefix is the default, @. It can be changed with
-p/--prefix=CHAR (environment variable: EMPY_PREFIX, configuration variable: prefix).
Markup |
Syntax |
Description |
Ver. |
|---|---|---|---|
|
Consumes text up to and including newline |
1.0 |
|
|
Consumes text up to and including the final asterisk(s) |
4.0 |
|
|
Consumes the following whitespace character |
1.0 |
|
|
Disables output |
4.2 |
|
|
(Re-)enables output |
4.2 |
|
|
Produces the prefix character |
1.0 |
|
|
Produces a string from a literal |
3.1.1 |
|
|
Quotes contained markup up to final backquote(s) |
4.0 |
|
|
Render an escape character |
1.5 |
|
|
Render an escape control character by name |
4.0 |
|
|
Evaluates an expression |
1.0 |
|
|
Evaluates a simple expression |
1.0 |
|
|
Evaluates a functional expression |
4.0 |
|
|
Expression evaluation with if-else-except |
1.3 |
|
|
Copies and evaluates an expression |
1.4 |
|
|
Executes a statement or statements |
1.0 |
|
|
Control structures |
3.0 |
|
|
Branching control structure |
3.0 |
|
|
Break out of repeating control structure |
3.0 |
|
|
Continue with next iteration of repeating control structure |
3.0 |
|
|
Iterating control structure |
3.0 |
|
|
Looping control structure |
3.0 |
|
|
Looping control structure always entered once ( |
4.0 |
|
|
Exception handling, guarding |
3.0 |
|
|
Handle a context manager |
4.0 |
|
|
Structural pattern matching |
4.1 |
|
|
Branch on whether a variable is defined |
4.0 |
|
|
Define an EmPy function |
3.0 |
|
|
Render and normalize diacritic combiner(s) |
4.0 |
|
|
Render a customizable icon |
4.0 |
|
|
Render a customizable emoji |
4.0 |
|
|
Declare a significator (metadata assignment) |
1.2 |
|
|
Set the context filename |
3.0.2 |
|
|
Set the context line |
3.0.2 |
|
|
Fully-customizable markups with no set definition |
4.1 |
See also
The list of supported markup is available in the markup help topic
and is summarized here.
Escape markup: @\...#
Escape markup allows specifying individual non-printable
characters with a special readable syntax: @\.... It is inspired
by and extends the string literal escape codes from languages such as
C/C++ and Python.
Example 17: Escapes
Source: ⌨️
@# These are all a Latin uppercase A:
Binary: @\B{1000001}
Quaternary: @\q1001, @\Q{1001}
Octal: @\o101, @\O{101}
Hexadecimal (variable bytes): @\X{41}
Hexadecimal (one-byte): @\x41
Hexadecimal (two-byte): @\u0041
Hexadecimal (eight-byte): @\U00000041
By Unicode name: @\N{LATIN CAPITAL LETTER A}
Output: 🖥️
Binary: A
Quaternary: A, A
Octal: A, A
Hexadecimal (variable bytes): A
Hexadecimal (one-byte): A
Hexadecimal (two-byte): A
Hexadecimal (eight-byte): A
By Unicode name: A
The escape sequence type is indicated by the first character and then
consumes zero or more characters afterward, depending on the escape
sequence. Some sequence sequences support a variable number of
characters, delimited by curly braces ({...}).
See also
The list of all valid escape sequences is available in the escapes
help topic and is summarized here.
New in version 1.5: Escape markup was introduced in EmPy version 1.5, and then reworked in EmPy version 4.0.
Named escape markup: @\^{...}#
The escape markup for controls @\^... has an extended usage where
the character can be specified by a control code name. The resulting
named escape markup takes the form of @\^{...} with the escape
code name between the curly braces. The name of the escape code used
in the markup is case insensitive.
The mapping of escape names to characters is specified in the
configuration variable controls. The keys of this
dictionary must be in uppercase and the values can be integers
(Unicode code point values), lists of integers, or strings. They can
also take the form of a 2-tuple, where the first element is one of the
above values and the second element is a description string used for
displaying in help topics.
Example 18: Named escapes
Source: ⌨️
Normal space: [ ]
Normal space by name: [@\^{SP}]
No-break space: [@\^{NBSP}]
Thin space: [@\^{THSP}]
En space: [@\^{ENSP}]
Em space: [@\^{EMSP}]
(Well, these would look right if it this were in a proportional font.)
Output: 🖥️
Normal space: [ ]
Normal space by name: [ ]
No-break space: [ ]
Thin space: [ ]
En space: [ ]
Em space: [ ]
(Well, these would look right if it this were in a proportional font.)
Note
The dictionary mapping all named escape codes to characters is stored in the
controls configuration variable. This can be
modified or completely replaced as desired. The values will be
recoded to a native string and can be any of the following, in
order:
a
str, representing the string;a
bytes, which will be decoded into a string according to the output encoding;an
int, representing the Unicode code point value, which will be converted to a string viachr;a callable object, which will be called and then converted;
any object with a
__str__method, whosestrvalue will be used;
or a list of the above values, which will be converted as above and
concatenated together.
Additionally, they can take the form of a 2-tuple, where the first element is one of the above types and the second element is a description string, used for rendering the value in help topics.
See also
The list of all valid control code names is available in the
named help topic and is summarized
here.
New in version 4.0: Named escape markup was introduced in EmPy version 4.0.
Expression markup: @(...)#
EmPy mainly processes markups by evaluating expressions and executing
statements. Expressions are bits of Python code that return a value;
that value is then rendered into the output stream. Simple examples
of Python expressions are 1 + 2, abs(-2), or "test"*3.
In EmPy, expressions are evaluated and expanded with the expression
markup @(...). By default, an expression that evaluates to
None does not print anything to the underlying output stream; this
is equivalent to it having returned ''.
Tip
If you want to change this behavior, specify your preferred value with
--none-symbol (configuration variable: noneSymbol).
Example 19: Expressions
Source: ⌨️
The sum of 1 and 2 is @(1 + 2).
The square of 3 is @(3**2).
The absolute value of -12 is @(abs(-12)).
This prints "test" but does not print None: @(print("test", end='')).
This, however, does: @(repr(None)).
Output: 🖥️
The sum of 1 and 2 is 3.
The square of 3 is 9.
The absolute value of -12 is 12.
This prints "test" but does not print None: test.
This, however, does: None.
Attention
Note that when markup which has starting and ending delimiters appears
alone on a line, the trailing newline will be rendered in the output.
To avoid these extra newlines, use a trailing @ to turn it
into whitespace markup which consumes that trailing newline, so e.g.
@(...) followed by
a newline becomes @(...)@ followed by a newline. This is idiomatic for
suppressing unwanted newlines. See here for more details.
New in version 1.0: Expression markup was introduced in EmPy version 1.0.
Additional expression markup#
Several expression markup variants are available.
Simple expression markup: @x, @x.a, @x[i], @x(args...), etc.#
Often expressions are “simple” and unambiguous enough that needing to
use the full @(...) syntax is unnecessary. In cases where a
single variable is being referenced unambiguously, the parentheses can
be left off to create simple expression markup:
Example 20: Simple expressions, basic
Source: ⌨️
@# Set a variable to use.
@{x = 16309}@
The value of x is @x.
Output: 🖥️
The value of x is 16309.
@x is precisely the same thing as @(x).
This markup can be extended further. Attribute references (@x.a),
indexing (@x[i]), and function calls (@x(args...)) can also be
simplified in this way. They can also be chained together
arbitrarily, so @object.attribute.subattribute,
@object.method(arguments...), @object[index1][index2],
@object[index].attribute, @object[index].method(arguments...),
etc. are all valid examples of simple expression markup. Function
calls can even be chained in simple expression markup:
@factory(identifier)(arguments...). These simple expressions can
be extended arbitrarily.
Example 21: Simple expressions, chaining
Source: ⌨️
@# Define some variables to use.
@{
import time
def mean(seq): # a function
return sum(seq)/len(seq)
class Person: # a class
def __init__(self, name, birth, scores):
self.name = name
self.birth = birth
self.scores = scores
def age(self):
current = time.localtime(time.time()).tm_year
return current - self.birth
person = Person("Fred", 1984, [80, 100, 70, 90]) # an instance of that class
}@
The name of person is @(person.name), or more simply @person.name.
The first letter is @(person.name[0]), or more simply @person.name[0].
He has @(len(person.scores)) scores, or more simply @len(person.scores).
His first score is @(person.scores[0]), or more simply @person.scores[0].
His average score is @(mean(person.scores)), or more simply @mean(person.scores).
His age is @(person.age()), or more simply @person.age().
Output: 🖥️
The name of person is Fred, or more simply Fred.
The first letter is F, or more simply F.
He has 4 scores, or more simply 4.
His first score is 80, or more simply 80.
His average score is 85.0, or more simply 85.0.
His age is 42, or more simply 42.
Note
Final punctuation, including a period (.), is not interpreted as an
attribute reference and thus does not result in a parse error. Thus
you can use end-of-sentence punctuation naturally after a simple
expression markup.
If you wish to concatenate an expression with immediately following text so that it will not be parsed incorrectly, either use whitespace markup or just fall back to a full expression markup:
Example 22: Simple expressions, concatenation
Source: ⌨️
@# Define a variable for use.
@{thing = 'cat'}@
@# Referencing `@things` to pluralize `@thing` will not work. But:
The plural of @thing is @thing@ s.
Or: The plural of @thing is @(thing)s.
Output: 🖥️
The plural of cat is cats.
Or: The plural of cat is cats.
New in version 1.0: Simple expression markup was introduced in EmPy version 1.0.
Functional expression markup: @function{markup}{...}#
Arguments to function calls in EmPy expression markups use Python
expressions, not EmPy markup (e.g., @f(x) calls the function f
with the variable x). To specify EmPy markup which is expanded and
then passed in to the function, there is functional expression
markup as an extension of simple expression markup. Since each
argument to the function is expanded, the arguments are always
strings:
Example 23: Functional expressions, one argument
Source: ⌨️
@{
def f(x):
return '[' + x + ']'
}@
@# Note that the argument is expanded before being passed to the function:
This will be in brackets: @f{1 + 1 is @(1 + 1)}.
Output: 🖥️
This will be in brackets: [1 + 1 is 2].
Functional expressions support the application of multiple arguments
by repeating the {...} suffix for as many arguments as is desired.
Each argument is expanded one at a time in order, from left to right:
Example 24: Functional expressions, multiple arguments
Source: ⌨️
@{
def f(x, y, z):
return x.lower() + ', ' + y.upper() + ', ' + z.capitalize()
}@
@# Multiple arguments are possible by repeating the pattern:
These expansions are separated by commas: @
@f{lowercase: @(1)}{uppercase: @(1 + 1)}{capitalized: @(1 + 1 + 1)}.
Output: 🖥️
These expansions are separated by commas: lowercase: 1, UPPERCASE: 2, Capitalized: 3.
The opening and closing curly braces can be repeated an equal number of times to allow curly braces to be used within the markup:
Example 25: Functional expressions, repeated braces
Source: ⌨️
@{
def f(*args):
return ''.join('[' + x + ']' for x in args)
}@
@# Repeated matching curly braces allow internal curly braces to be used:
This contains internal curly braces: @f{{There are {curly braces} inside}}.
This contains more: @f{{{Even more {curly} {{braces}} here}}}.
@# To have internal curly braces at the start or end,
@# use escape markup or whitespace markup to separate them:
Internal curly braces with whitespace: @f{{@ {braces}@ }}.
Internal curly braces with escapes: @f{@\{braces@\}}.
Internal curly braces with hexdecimal escapes: @f{@\x7bbraces@\x7d}.
Output: 🖥️
This contains internal curly braces: [There are {curly braces} inside].
This contains more: [Even more {curly} {{braces}} here].
Internal curly braces with whitespace: [{braces}].
Internal curly braces with escapes: [{braces}].
Internal curly braces with hexdecimal escapes: [{braces}].
Warning
Functional expression markup is an extension of simple expression
markup so cannot be used in standard expression markup. Further, it
cannot be seemlessly combined (“curried”) with a normal function call.
Thus, @f(1){a}{b} is equivalent to @(f(1)('a', 'b')), not
@(f(1, 'a', 'b')). A functional argument calls will terminate
simple expression parsing, so @f{a}{b}(3) is the same as @(f('a', 'b'))(3), not @f('a', 'b', 3); that is, trailing function calls
are not applied.
New in version 4.0: Functional expression markup was introduced in EmPy version 4.0.
Extended expression markup: @(...?...!...$...)#
Expression markup has an extended expression markup form which allows more powerful manipulation of expressions.
Conditional expression markup: @(...?...!...)#
The first form is conditional expression markup which allows for a
compact form of an @[if] statement with a ternary operator, similar
to C/C++’s ? and : operators. In EmPy, however, these are
represented with ? and !, respectively.
Note
C/C++’s use of : was changed to ! for EmPy since : already has
special meaning in Python. This syntax was originally added before
Python supported the if/else ternary expression, although EmPy’s
syntax is more general and powerful.
If a ? is present in the expression, then the Python (not EmPy)
expression before the ? is tested; if it is true, then the Python
expression following it is evaluated. If a ! is present afterward
and the originally expression was false, then the Python expression
following it is expanded (otherwise, nothing is). It thus acts as an
if-then-else construct:
Example 26: Extended expressions, conditional
Source: ⌨️
Four is an @(4 % 2 == 0 ? 'even' ! 'odd') number.
Five is @(5 % 2 == 0 ? 'also even' ! 'not').
Seven is an @(7 % 2 == 0 ? 'even' ! 'odd') number.
And this is blank: @(False ? 'this will expand to nothing')
@# Whitespace is not required:
Eleven is an @(11 % 2 == 0?'even'!'odd') number.
Output: 🖥️
Four is an even number.
Five is not.
Seven is an odd number.
And this is blank:
Eleven is an odd number.
Chained conditional expression markup: @(...?...!... ...)#
These ? and ! sequences can be repeated indefinitely, forming an
if-else-if-else chain called chained conditional expression
markup, with a ! expression serving as the conditional test for
the next ?:
Example 27: Extended expressions, chained conditional
Source: ⌨️
@# Define a variable for use.
@{x = 3}@
x is @(x == 1 ? 'one' ! x == 2 ? 'two' ! x == 3 ? 'three' ! 'unknown').
Output: 🖥️
x is three.
Except expression markup: @(...$...)#
Finally, a $ present toward the end of expression markup, whether or
not it includes an if-else chain, represents except expression
markup: If the main expression throws an exception, suppress it and
evaluate the Python (not EmPy) except expression instead. This can be
combined with conditional or chained conditional expresion markup:
Example 28: Extended expressions, except
Source: ⌨️
No exception: 2 + 2 = @(2 + 2 $ 'oops').
Division by zero is @(1/0 $ 'illegal').
Two divided by zero is @(2/0 % 2 == 0 ? 'even' ! 'odd' $ 'also illegal').
Output: 🖥️
No exception: 2 + 2 = 4.
Division by zero is illegal.
Two divided by zero is also illegal.
Tip
Except expression markup will not capture SyntaxErrors, since it is
much more likely that this is a static error (e.g., a typographical
error) rather than a dynamic error. This behavior can be modified by
changing fallThroughErrors in the
configuration.
Attention
Note that when markup which has starting and ending delimiters appears
alone on a line, the trailing newline will be rendered in the output.
To avoid these extra newlines, use a trailing @ to turn it
into whitespace markup which consumes that trailing newline, so e.g.
@(...) followed by
a newline becomes @(...)@ followed by a newline. This is idiomatic for
suppressing unwanted newlines. See here for more details.
New in version 1.3: Conditional expression markup was first introduced in EmPy version 1.3, updated to extended expressions (including exception handling) in EmPy version 1.4, and was expanded to support if-else chained conditional expressions in 4.0.
In-place expression markup: @$...$...$#
Occasionally it’s desirable to designate an expression that will be
evaluated alongside its evaluation which may change, but which will be
re-evaluated with subsequent updates, in other words, explicitly
identifying exactly what is being evaluated at the same time. This is
similar to the notion of CVS or SVN keywords such as $Date ...$.
For this, there is in-place expression markup (@$...$...$).
They consist of two segments: first, the Python (not EmPy) expression
to evaluate, and the second, the result of that evaluation. When
evaluating the markup, the second (result) section is ignored and
replaced with the evaluation of the first and a new in-place markup is
rendered. For example:
Example 29: In-place expressions
Source: ⌨️
This could be a code comment indicating the version of EmPy:
# @$empy.version$this text is replaced with the result$
Arbitrary Python expressions can be evaluated:
# @$__import__('time').asctime()$$
Output: 🖥️
This could be a code comment indicating the version of EmPy:
# @$empy.version$4.2.1$
Arbitrary Python expressions can be evaluated:
# @$__import__('time').asctime()$Wed Mar 18 19:19:06 2026$
Note
The $ character is a common choice for an alternate prefix. If it
is chosen instead of the default @, the in-place expression markup
will be remapped to have the form $@...@...@; that is, the @
and $ are swapped. (This is done automatically for any prefix
collision with a markup indicator.)
Attention
Note that when markup which has starting and ending delimiters appears
alone on a line, the trailing newline will be rendered in the output.
To avoid these extra newlines, use a trailing @ to turn it
into whitespace markup which consumes that trailing newline, so e.g.
@$...$...$ followed by
a newline becomes @$...$...$@ followed by a newline. This is idiomatic for
suppressing unwanted newlines. See here for more details.
New in version 1.4: In-place markup was introduced in EmPy version 1.4.
Statement markup: @{...}#
Again, EmPy mainly processes markups by evaluating expressions and
executing statements. Statements include assignments, control
structures (if, for, function and class definitions, etc.)
Statements do not yield a value; they are used for side effects,
whether that’s changing the state of the interpreter (setting or
changing variables, defining objects, calling functions, etc.) or
printing output. Statements can also consist of expressions, so an
expression (such as print("Hello, world!")) can be used solely for
its side effects with the statement markup. Statement markup sets
off a series of statements to be executed inside the @{...}
markup. Since statements do not yield a value, they are executed but
the markup itself does not implicitly write anything. Since the
executed statements are Python, multiline statements must be formatted
and indented according to Python’s parsing rules:
Example 30: Statements
Source: ⌨️
@# Note the use of whitespace markup below to consume trailing newlines.
@{x = 16309}@
x is now @x.
@{
if x > 0:
category = 'positive'
else:
category = 'non-positive'
print("x is {}.".format(category))
}@
@{
# Since statement markup does not write anything itself, this
# statement has no effect.
x + 123
}@
Output: 🖥️
x is now 16309.
x is positive.
Attention
Note that when markup which has starting and ending delimiters appears
alone on a line, the trailing newline will be rendered in the output.
To avoid these extra newlines, use a trailing @ to turn it
into whitespace markup which consumes that trailing newline, so e.g.
@{...} followed by
a newline becomes @{...}@ followed by a newline. This is idiomatic for
suppressing unwanted newlines. See here for more details.
New in version 1.0: Statement markup was introduced in EmPy version 1.0.
Control markups: @[...]#
EmPy supports a variety of control structures, analogous to the
builtin Python control structures (if, while, for, etc.), with
some additional markups for convenience. This is done with control
markup indicated by @[...].
Since EmPy cannot rely on source indentation to delimit control
structure syntax, all primary control markups must end with an
explicit end markup (e.g., @[if ...]...@[end if]). The clauses
surrounded by control markup are EmPy (Python) markup and are expanded
according to the logic of each control markup; see below.
Unlike the Python control structures, the code that is expanded within
each subclause is EmPy code, not Python code. Thus, control markups
can be nested arbitrarily (e.g., @[while ...]@[for ...]@[if ...]...@[end if]@[end for]@[end while]).
Attention
To use nested control markup that spans multiple lines and is more readable, you can rely on whitespace markup to consume the newline immediately following the control markup. As an example:
Example 31: Controls, idiom
Source: ⌨️
@# Note the user of whitespace markup to consume the trailing newlines.
Counting:
@[for i, x in enumerate(range(0, 5))]@
@x is @
@[ if x % 2 == 0]@
even@
@[ else]@
odd@
@[ end if]@
.
@[end for]@
Output: 🖥️
Counting:
0 is even.
1 is odd.
2 is even.
3 is odd.
4 is even.
This method of writing organizing control markup with @[...]@ all
on a single line for clarity is idiomatic EmPy. (This applies to all
markup with starting and ending delimiters.) See here for
more details.
Hint
Whitespace before the control keyword is ignored, so you can add whitespace inside the markup to simulate Python indentation for clarity, as the above example demonstrates.
Tip
Simple (“clean”) control markup which does not contain arbitrary
Python expressions — @[try], @[else], @[except ...],
@[finally], @[continue], @[break] and @[end ...] — can
include a Python-style comment for clarity:
Example 32: Controls, clean
Source: ⌨️
@{
number = 42
test = 3%2 == 0
}@
@[if test]@
@number is even.
@# Say there were many more lines here ...
@[else # test]@
@number is not even.
@# And also here ...
@[end if # test]@
Output: 🖥️
42 is not even.
New in version 3.0: Control markups were introduced in EmPy version 3.0 unless otherwise noted below.
If control markup: @[if E]...@[end if]#
The simplest control markup is the if control markup. It
precisely mimics the Python if branching control structure. The
test expressions are Python expressions. Like the native Python
control structure, it takes on the following forms:
@[if E]...@[end if]@[if E]...@[else]...@[end if]@[if E1]...@[elif E2]...@[end if]@[if E1]...@[elif E2]...@[else]...@[end if]@[if E1]...@[elif E2]...@[elif E3]...@[else]...@[end if]@[if E1]...@[elif E2]...@[elif E3]... ... @[else]...@[end if]
where the Es are Python expressions to be tested for truth.
Thus, as with the builtin Python if control structure, zero or more
@[elif] clauses can be used and the @[else] clause (only valid
at the end of the chain) is optional. If there is no @[else]
clause and all the test expressions are false, nothing will be
expanded.
Example 33: If controls
Source: ⌨️
@{
def even(x):
return x % 2 == 0
}@
0 is @[if even(0)]even@[end if].
1 is @[if even(1)]even@[else]odd@[end if].
2 is @[if even(2)]even@[else]odd@[end if].
3 is @[if even(3)]even@[elif not even(3)]not even@[end if].
4 is @[if 0 == 1]wrong@[elif 1 == 2]wrong@[else]fine@[end if].
Output: 🖥️
0 is even.
1 is odd.
2 is even.
3 is not even.
4 is fine.
Break and continue control markup: @[break], @[continue]#
The looping control markup structures below (@[for], @[while],
and @[dowhile]) all support break and continue control
markup. These markups follow the native Python forms; @[break]
will exit out of the innermost looping control structure, and
@[continue] will restart the innermost looping control structure.
They take the following forms:
@[break]@[continue]
What follows is a few examples using a @[for] loop:
Example 34: Continue controls
Source: ⌨️
@# Print even numbers.
@[for n in range(10)]@
@[ if n % 2 != 0]@
@[ continue]@
@[ end if]@
@n is even.
@[end for]@
Output: 🖥️
0 is even.
2 is even.
4 is even.
6 is even.
8 is even.
Example 35: Break controls
Source: ⌨️
@# Print numbers up to (but not including) 5.
@[for n in range(10)]@
@[ if n >= 5]@
@[ break]@
@[ end if]@
@n is less than 5.
@[end for]@
Output: 🖥️
0 is less than 5.
1 is less than 5.
2 is less than 5.
3 is less than 5.
4 is less than 5.
For control markup: @[for N in E]...@[end for]#
A basic iteration markup is the for control markup. It precisely
mimics the Python for looping control structure. The iterator
expression is a Python expression. Like the native Python control
structure, it takes on the following forms:
@[for N in E]...@[end for]@[for N in E]...@[else]...@[end for]
where N is a Python identifier and E is a Python expression
which is iterable.
As with the native Python control structure, an @[else] clause is
supported; this is expanded if the loop exits without an intervening
break.
Example 36: For controls
Source: ⌨️
@[for x in range(1, 6)]@
@x squared is @(x*x).
@[else]@
... and done.
@[end for]@
Output: 🖥️
1 squared is 1.
2 squared is 4.
3 squared is 9.
4 squared is 16.
5 squared is 25.
... and done.
While control markup: @[while E]...@[end while]#
The most general looping markup is the while control markup. It
precisely mimics the Python while looping control structure. The
test expression is a python expression. Like the native Python
control structure, it takes on the following forms:
@[while E]...@[end while]@[while E]...@[else]...@[end while]
where E is a Python expression to be tested for truth.
As with the native Python control structure, an @[else] clause is
supported; this is invoked if the loop exits without an intervening
break.
Example 37: While controls
Source: ⌨️
@{a = 1}@
@[while a <= 5]@
@a pound signs: @('#'*a).
@{a += 1}@
@[else]@
... and done.
@[end while]@
Output: 🖥️
1 pound signs: #.
2 pound signs: ##.
3 pound signs: ###.
4 pound signs: ####.
5 pound signs: #####.
... and done.
Dowhile control markup: @[dowhile E]...@[end dowhile]#
An alternate while control structure is provided by EmPy: dowhile
control markup. This differs from the standard while markup only
in that the loop is always entered at least once; that is, the test
expression is not checked before the first iteration. In this way, it
is similar to the do ... while control structure from C/C++. It
takes the following forms:
@[dowhile E]...@[end dowhile]@[dowhile E]...@[else]...@[end dowhile]
where E is a Python expression to be tested for truth.
Like the native Python while control structure, an @[else] clause
is supported; this is invoked if the loop exits without an intervening
break.
Example 38: Dowhile controls
Source: ⌨️
@# Stop when divisible by 5, but include 0 since it's the first iteration:
@{n = 0}@
@[dowhile n % 5 != 0]@
@n works@[if n % 5 == 0] (even though it's divisible by 5)@[end if].
@{n += 1}@
@[else]@
... and done.
@[end dowhile]@
Output: 🖥️
0 works (even though it's divisible by 5).
1 works.
2 works.
3 works.
4 works.
... and done.
New in version 4.0: Dowhile control markup was introduced in EmPy version 4.0.
Try control markup: @[try]...@[end try]#
Try control markup is the EmPy equivalent of a try statement.
As with the native Python statement, this markup can take on the
widest variety of forms. They are:
@[try]...@[except]...@[end try]@[try]...@[except C]...@[end try]@[try]...@[except C as N]...@[end try]@[try]...@[except C, N]...@[end try]@[try]...@[except (C1, C2, ...) as N]...@[end try]@[try]...@[except C1]...@[except C2]...@[end try]@[try]...@[except C1]...@[except C2]... ... @[end try]@[try]...@[finally]...@[end try]@[try]...@[except ...]...@[finally]...@[end try]@[try]...@[except ...]...@[else]...@[end try]@[try]...@[except ...]...@[else]...@[finally]...@[end try]
where the Cs are Python expressions to be treated as an exception
class or tuple of classes and N is a Python identifier.
Its behavior mirrors in every way the native Python try statement.
The try clause will be expanded, and if an exception is thrown, the
first @[except] clause that matches the thrown exception (if there
are any) will be expanded. If a @[finally] clause is present, that
will be expanded after any possible exception handling, regardless of
whether an exception was in fact thrown. Finally, if there is at
least one @[except] clause, an @[else] may be present which will
be expanded in the event that no exception is thrown (but before any
@[finally] clause).
The argument to the @[except] markup indicates which type(s) of
exception should be handled and with what name, if any. No argument
indicates that it will handle any exception. A simple expression will
indicate an exception class, or a tuple of exception classes, that
will be handled. The variable name of the thrown exception can be
captured and passed to the expansion with the as keyword, or a comma
(this latter notation is invalid in modern Python versions but is
still supported in EmPy regardless of the underlying Python version).
For example:
Example 39: Try controls
Source: ⌨️
Garbage is @[try]@hugalugah@[except NameError]not defined@[end try].
Division by zero is @[try]@(1/0)@[except ZeroDivisionError]illegal@[end try].
An index error is @[try]@([][3])@[except IndexError as e]@e.__class__.__name__@[end try].
And finally: @[try]@(nonexistent)@[except]oops, @[finally]something happened@[end try].
Output: 🖥️
Garbage is not defined.
Division by zero is illegal.
An index error is IndexError.
And finally: oops, something happened.
New in version 3.0: Try control markup was introduced in EmPy version 3.0, and was
expanded in 4.0 to include all modern valid uses of @[else] and
@[finally].
With control markup: @[with E as N]...@[end with]#
EmPy supports a version of the with statement, which was introduced
in Python 2.5. In EmPy, the with control markup is written as
@[with] and mirrors the behavior of the native with statement.
It takes the following forms:
@[with E as N]...@[end with]@[with N]...@[end with]@[with E]...@[end with]
where E is a Python expression which is iterable and N is a
Python identifier.
All forms use context managers, just as with the native statement.
Context managers are objects which have __enter__ and __exit__
methods, and the @[with] markup ensures that the former is called
before the markup’s contents are expanded and that the latter is
always called afterward, whether or not an exception has been thrown.
The three forms of the @[with] markup mirror the uses of the with
keyword: The user can specify an expression and a variable name with
the as keyword, or just a variable name, or just an expression (it
will be entered and exited, but the name of the resulting object will
not be available). For example:
Example 40: With controls
Source: ⌨️
@{
import os, sys
# Create a test file to use with the @[with ...] markup.
with open('/tmp/with.txt', 'w') as f:
print("Hello, world!", file=f)
}@
@[with open('/tmp/with.txt') as f]@f.read()@[end with]@
Output: 🖥️
Hello, world!
Note
Although the with keyword was only introduced in Python 2.5, the
@[with] markup will work in any supported version of Python.
New in version 4.0: With control markup was introduced in EmPy version 4.0.
Match control markup: @[match E]@[case C]...@[end match]#
Python 3.10 introduces structural pattern matching with the
match/case control structure. The analog to this in EmPy is the
match control markup. It takes the following forms:
@[match E]@[case C1]...@[end match]@[match E]@[case C1]...@[case C2]...@[end match]@[match E]@[case C1]...@[case C2]...@[else]...@[end match]
where E is a Python expression to be matched and the Cs are
Python expressions to be tested as match cases.
The control markup behaves the same as the native Python control
structure: The first @[case] clause which matches is expanded
and the control finishes. An optional @[else] clause can appear at
the end of the chain of cases and will be expanded if no previous
@[case] clause matches; @[else] is identical to @[case _].
Markup that is present between the @[match] markup and the first
@[case] is unconditionally expanded. Typically this will be markup
that expands to nothing, but it can involve a preamble if desired.
Example 41: Match controls
Source: ⌨️
@[for p in [(0, 0), (10, 0), (0, 10), (10, 10), (10, 20), (20, 10), 'oops']]@
@[ match p]@
@# Markup here is expanded unconditionally.
@p is @
@[ case (0, 0)]@
the origin.
@[ case (0, y)]@
y = @y.
@[ case (x, 0)]@
x = @x.
@[ case (x, y) if x == y]@
x = y = @x.
@[ case (x, y)]@
x = @x, y = @y.
@[ else]@
not a point.
@[ end match]@
@[end for]@
Output: 🖥️
(0, 0) is the origin.
(10, 0) is x = 10.
(0, 10) is y = 10.
(10, 10) is x = y = 10.
(10, 20) is x = 10, y = 20.
(20, 10) is x = 20, y = 10.
oops is not a point.
Warning
Since the @[match] markup relies on the underlying Python
functionality, using this markup with a version of Python before 3.10
will result in a CompatibilityError being raised.
New in version 4.1: Match control markup was introduced in EmPy version 4.1.
Defined control markup: @[defined N]...@[end defined]#
Sometimes it’s useful to know whether a name is defined in either the locals or globals dictionaries. EmPy provides a dedicated markup for this purpose: defined control markup. It takes the following forms:
@[defined N]...@[end defined]@[defined N]...@[else]...@[end defined]
where N is a Python identifier.
When provided a name, it will expand the contained markup if that name
is defined in either the locals or globals. @[defined NAME]...@[end defined] is equivalent to @[if 'NAME' in globals() or 'NAME' in locals()]...@[end if]. An @[else] clause is also supported; if
present, this will be expanded if the name does not appear in the
locals or globals. If no @[else] clause is present and the name is
not defined, nothing will be expanded.
Example 42: Defined controls
Source: ⌨️
@{cat = 'Boots'}@
Cat is @[defined cat]@cat@[else]not defined@[end defined].
Dog is @[defined dog]@dog@[else]not defined@[end defined].
Output: 🖥️
Cat is Boots.
Dog is not defined.
New in version 4.0: Defined control markup was introduced in EmPy version 4.0.
Def control markup: @[def F(...)]...@[end def]#
EmPy supports defining functions which expand EmPy code, not Python
code as with the standard def Python statement. This is called
def control markup. It takes on the following form:
@[def F(...)]...@[end def]
where F(...) is a Python function signature.
Def control markup involves specifying the signature of the resulting
function (such as with the standard Python def statement) and
encloses the EmPy code that the function should expand. It is then
defined in the interpreter’s globals/locals and can be called like any
other Python function.
It is best demonstrated with a simple example:
Example 43: Def controls
Source: ⌨️
@# Define an EmPy-native function.
@[def element(name, symbol, atomicNumber, group)]@
Element @name (symbol @symbol, atomic number @atomicNumber) is a @group@
@[end def]@
@# Now use it.
@element('hydrogen', 'H', 1, 'reactive nonmetal').
@element('helium', 'He', 2, 'noble gas').
@element('lithium', 'Li', 3, 'alkali metal').
@element('beryllium', 'Be', 4, 'alkaline earth metal').
@element('boron', 'B', 5, 'metalloid').
@element('carbon', 'C', 6, 'reactive nonmetal').
Output: 🖥️
Element hydrogen (symbol H, atomic number 1) is a reactive nonmetal.
Element helium (symbol He, atomic number 2) is a noble gas.
Element lithium (symbol Li, atomic number 3) is a alkali metal.
Element beryllium (symbol Be, atomic number 4) is a alkaline earth metal.
Element boron (symbol B, atomic number 5) is a metalloid.
Element carbon (symbol C, atomic number 6) is a reactive nonmetal.
Hint
The markup @[def FUNC(...)]DEFN@[end def] is equivalent to the
following Python code:
def FUNC(...):
r"""DEFN"""
return empy.expand(r"""DEFN""", locals())
It simply defines a Python function with the provided signature, a
docstring indicating its EmPy definition, and the function calls the
expand method on the pseudomodule/interpreter with the definition
and returns the results.
Any valid Python function notation is allowed, including type hints;
note, though, that the return value of the defined function is an
expansion and thus should always be str:
Example 44: Def controls: type hints
Source: ⌨️
@{
DIGITS = [
'zero', 'one', 'two', 'three', 'four',
'five', 'six', 'seven', 'eight', 'niner',
]
}@
@[def words(number: int) -> str]@
@(' '.join(DIGITS[int(x)] for x in str(number)))@
@[end def]@
16309 in words is @words(16309).
Output: 🖥️
16309 in words is one six three zero niner.
Tip
Functions defined with def control markup are callable Python objects
like any other. They can be called through any mechanism, whether
Python (f(...)), through EmPy markup (@f(...)), or even via
functional expression markup
(@f{...}).
Diacritic markup: @^ CHAR DIACRITIC(S)#
EmPy provides a quick and convenient way to combine diacritics
(accents) to characters with diacritic markup. Diacritic markup
consists of the prefix @^, followed by the base character, and then
either a single character representing the accent to apply or a
sequence of such characters enclosed in curly braces ({...}).
The first character is the base character to combine diacritics with,
and the remaining characters (possibly more than one if the curly
braces form is used) are diacritic codes corresponding to Unicode
combining characters that can be combined (or just appended) to the
base character. These combining diacritics are simpler, more easily
entered characters that (at least in some cases) resemble the actual
desired combining character. For instance, ' (apostrophe)
represents the acute accent ◌́; ` (backquote) represents the grave accent ◌̀; ^ represents the circumflex
accent ◌̂, and so on:
Example 45: Diacritics
Source: ⌨️
French: Voil@^a`, c'est ici que @^c,a s'arr@^e^te.
Spanish: Necesito ir al ba@^n~o ahora mismo.
Portuguese: Informa@^c,@^a~o @^e' poder.
Swedish: Hur m@^aonga kockar kr@^a:vs f@^o:r att koka vatten?
Vietnamese: Ph@^o{h?} b@^o` vi@^e^n ngon qu@^a'!
Esperanto: E@^h^o@^s^an@^g^e @^c^iu@^j^a@^u(de!
Shakespearean: All are punish@^e`d.
Output: 🖥️
French: Voilà, c'est ici que ça s'arrête.
Spanish: Necesito ir al baño ahora mismo.
Portuguese: Informação é poder.
Swedish: Hur många kockar krävs för att koka vatten?
Vietnamese: Phở bò viên ngon quá!
Esperanto: Eĥoŝanĝe ĉiuĵaŭde!
Shakespearean: All are punishèd.
Tip
Curly braces can enclose zero or more characters representing
diacritics. If they enclose zero, the diacritic markup has no effect
(@^e{} is no different from e). If they enclose one, the results
are no different from not using curly braces (@^e{'} and @^e'
are have identical results). Only when applying more than one
diacritic are curly braces required.
By default, the base character and diacritics will be combined with
NFKC normalization — this will, when possible, replace the base
character and its combiners with a single Unicode character
representing the combination, if one exists. Normalization is not
required (and may sometimes fail when a suitable combined form does
not exist); in these cases, your system’s Unicode renderer will cope
as best it can. To change the normalization type, use
-z/--normalization-form=F (configuration variable: normalizationForm). To disable normalization,
set it to the empty string.
Note
The dictionary mapping all diacritic codes to combining characters is stored in the
diacritics configuration variable. This can be
modified or completely replaced as desired. The values will be
recoded to a native string and can be any of the following, in
order:
a
str, representing the string;a
bytes, which will be decoded into a string according to the output encoding;an
int, representing the Unicode code point value, which will be converted to a string viachr;a callable object, which will be called and then converted;
any object with a
__str__method, whosestrvalue will be used;
or a list of the above values, which will be converted as above and
concatenated together.
Additionally, they can take the form of a 2-tuple, where the first element is one of the above types and the second element is a description string, used for rendering the value in help topics.
See also
The list of all default diacritic codes is available in the
diacritics help topic and is summarized
here.
New in version 4.0: Diacritic markup was introduced in EmPy version 4.0.
Icon markup: @|...#
A customizable brief way to map “icon” keys — short, user-specified
strings — to arbitrary Unicode strings exists in the form of icon
markup. Icon markup is set off with @|... and then followed by
an unambiguous, arbitrary-length sequence of characters (Unicode code
points) corresponding to one of its keys.
Keys can be arbitrary length and can consist of whatever characters
are desired (including letters, numbers, punctuation, or even Unicode
characters). They are not delimited by whitespace; however, they must
be unambiguous, so if more than one key exists with the same prefixes
(say, @|#+ and @|#-), a key cannot be assigned the common prefix
(@|#) as this would be found first and would hide the longer
prefixes. Such a common prefix key should be set to the value None
(which indicates to the parser that the icon is potentially valid but
not yet complete).
This validation is done automatically when the icon markup is first
used: The dictionary of icons is traversed and any common prefixes not
defined in the dictionary are set to None. In the event that this
auto-validation may be expensive and the user wishes to do it manually
to avoid this step, specify the
--no-auto-validate-icons command line option
(autoValidateIcons configuration variable) to disable
it.
To customize icons, modify or replace the icons
configuration variable:
Note
The dictionary mapping all icon keys to their substitutes is stored in the
icons configuration variable. This can be
modified or completely replaced as desired. The values will be
recoded to a native string and can be any of the following, in
order:
a
str, representing the string;a
bytes, which will be decoded into a string according to the output encoding;an
int, representing the Unicode code point value, which will be converted to a string viachr;a callable object, which will be called and then converted;
any object with a
__str__method, whosestrvalue will be used;
or a list of the above values, which will be converted as above and
concatenated together.
Additionally, they can take the form of a 2-tuple, where the first element is one of the above types and the second element is a description string, used for rendering the value in help topics.
Tip
If you’re finding problems with icons being ambiguous, you can add
delimiters at the end of the icon key to ensure that they are
unambiguous. For example, the icons @|!, @|!! and @|!? would
normally be ambiguous. However, wrapping them in, say, curly braces,
will remove the ambiguity: @|{!}, @|{!!}, @|{!?} are
unambiguous and can be used as icon keys.
See also
The list of all valid icon keys is available in the icons help topic
and is summarized here.
Warning
The default set of icons were chosen by the author for his convenience and to demonstrate what icon markup can do. It is expected that users using icon markup will modify (or more likely completely replace) the icons dictionary to their liking. Thus the default icons are subject to change.
New in version 4.0: Icon markup was introduced in EmPy version 4.0.
Emoji markup: @:...:#
A dedicated emoji markup is available to translate Unicode emoji
names, and Unicode names more generally, into Unicode glyphs. Using
the markup is simple: Use the @:...: syntax and put the name of the
emoji character between the colons. Since EmPy is often used in
wrapped text, any newlines in the emoji name will be replaced with
spaces.
By default it uses the builtin unicodedata.lookup function call
which allow the lookup of any Unicode code point by name, not just
emoji. Whether names are case sensitive or not, or whether words are
separated by spaces or underscores or either, is module-dependent.
The builtin unicodedata module (the fallback if no emoji-specific
modules are installed) is case insensitive and requires spaces, not
underscores:
Example 48: Emojis
Source: ⌨️
Latin capital letter A: @:LATIN CAPITAL LETTER A:
Latin small letter O with diaeresis: @:latin small letter o with diaeresis:
White heavy check mark: @:WHITE HEAVY CHECK MARK:
Volcano: @:VOLCANO:
Output: 🖥️
Latin capital letter A: A
Latin small letter O with diaeresis: ö
White heavy check mark: ✅
Volcano: 🌋
User-specified emojis can also be assigned to the
emojis configuration variable; these will be checked
before any emoji modules are queried. Emojis in the emojis
dictionary are case sensitive:
Example 49: Emojis, custom
Source: ⌨️
@# What's with this guy and cats?
@{
empy.config.emojis['kittycat'] = '\U0001f408'
}@
This is a kitty cat: @:kittycat:
Output: 🖥️
This is a kitty cat: 🐈
Note
The dictionary mapping all emoji keys to their substitutes is stored in the
emojis configuration variable. This can be
added to or completely replaced as desired. The values will be
recoded to a native string and can be any of the following, in
order:
a
str, representing the string;a
bytes, which will be decoded into a string according to the output encoding;an
int, representing the Unicode code point value, which will be converted to a string viachr;a callable object, which will be called and then converted;
any object with a
__str__method, whosestrvalue will be used;
or a list of the above values, which will be converted as above and
concatenated together.
Additionally, they can take the form of a 2-tuple, where the first element is one of the above types and the second element is a description string, used for rendering the value in help topics.
Third-party emoji modules#
The emoji markup can also use third-party emoji modules if they are
present. These can be installed in the usual way with PyPI (e.g.,
python3 -m pip install emoji) or any other preferred method. The
following emoji modules are supported:
Module |
Function |
Parameter |
Capitalization |
Word delimiters |
|---|---|---|---|---|
|
|
lowercase |
underscores |
|
|
|
lowercase |
underscores |
|
|
|
lowercase |
underscores |
|
|
|
|
both |
spaces |
On first usage, each module is checked to see if it is present and is
then registered in the order listed above. When a lookup on a name is
performed, each module which is present is queried in order, and if it
finds the given name, that is used as output. If no modules find the
name, by default an error is generated, but this behavior can be
changed with the --ignore-emoji-not-found command line
option.
The order in which modules are queried is also customizable with the
--emoji-modules command line option; specify the
sequence of emoji module names to test separated by commas. Use the
--no-emoji-modules command line option to only enable
the builtin unicodedata module lookup, deactivating the use of any
custom modules which may be installed. And use
--disable-emoji-modules to disable all emoji module
lookup; only the emojis configuration variable will be consulted.
In summary, after install the third-party emoji module you prefer —
or rely on the default standard module, unicodedata — and using the
emoji markup will “just work.”
If you’re aware of other third-party emoji modules you’d like to see supported, contact the author.
Tip
It’s expected that the typical EmPy user will have at most one
third-party module installed, so no effort has been put in place to
avoid conflicts or redundancies regarding emoji names between them
other than specifying the desired lookup order. Choose a third-party
module that works for you, or just rely on the builtin unicodedata
lookup table.
If you’re relying on a third-party module to be present, you might want to have your EmPy code explicitly import that module so that if it’s missing, the dependency will be called out prominently.
Attention
Note that when markup which has starting and ending delimiters appears
alone on a line, the trailing newline will be rendered in the output.
To avoid these extra newlines, use a trailing @ to turn it
into whitespace markup which consumes that trailing newline, so e.g.
@:...: followed by
a newline becomes @:...:@ followed by a newline. This is idiomatic for
suppressing unwanted newlines. See here for more details.
New in version 4.0: Emoji markup was introduced in EmPy version 4.0.
Significator markup: @%[!]... NL, @%%[!]...%% NL#
Significator markup is a way to perform distinctive assignments
within an EmPy system which are easily parsed externally; for
instance, for specifying metadata for an EmPy source document; these
assignments are called significators. In its simplest form, it
defines in a variable in the globals with the evaluation of a Python
value. The significator @%KEY VALUE is equivalent to the Python
assignment statement __KEY__ = VALUE.
The name of the assigned variable is preceded and ended with a double
underscore (__). (This behavior can be changed with
configurations.) Note that the value assigned can be any Python
expression, not just a string literal:
Example 50: Significators, basics
Source: ⌨️
@%title "A Tale of Two Cities"
@%author 'Charles Dickens'
@%year 1859
@%version '.'.join([str(x) for x in __import__('sys').version_info[0:2]])
The book is _@(__title__)_ (@__year__) by @__author__.
This version of Python is @__version__.
Output: 🖥️
The book is _A Tale of Two Cities_ (1859) by Charles Dickens.
This version of Python is 3.10.
Whitespace is allowed between the @% markup introducer and the key,
and any (non-newline) whitespace is allowed between the key and the
value. The ending newline is always consumed.
A variant of significator markup can span multiple lines. Instead of
using @% and a newline to delimit the significator, use @%% and
%% followed by a newline:
Example 51: Significators, multiline
Source: ⌨️
@%%longName "This is a potentially very long \
name which can span multiple lines." %%
@%%longerName """This is a triple quoted string
which itself contains newlines. Note the newlines
are preserved.""" %%
@%%longExpression [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]] %%
Long name: @__longName__
Longer name: @__longerName__
Long expression: @__longExpression__
Output: 🖥️
Long name: This is a potentially very long name which can span multiple lines.
Longer name: This is a triple quoted string
which itself contains newlines. Note the newlines
are preserved.
Long expression: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Note
When using multiline significators, the value must still be a valid Python expression. So the significator
@%%bad 1 + 2 + 3 +
4 + 5 + 6 %%
is a syntax error due to the intervening newline. To correct this,
use a backslash character (\) to escape the newline or enclose the
value expression in parentheses:
@%%good1 1 + 2 + 3 + \
4 + 5 + 6 %%
@%%good2 (1 + 2 + 3 +
4 + 5 + 6) %%
Two more subvariants of significator markup exists, one for each of
these two variants. Frequently significator values will just be
string literals and for uniformity users may wish to not deal with
full Python expressions. For these purposes, significator values can
be stringized, or treated merely as strings with no Python
evaluation. Simply insert a ! after the @% or @%% markup
introducer and before the name of the key:
Example 52: Significators, stringized
Source: ⌨️
@# These values are all implicit strings.
@%!single This is on a single line.
@%%!multi This is on
multiple lines. %%
Single line: @__single__
Multiple lines: @__multi__
Output: 🖥️
Single line: This is on a single line.
Multiple lines: This is on
multiple lines.
Finally, the values for both single and multiline significator markups
are optional. If the markup is not stringized, the value will be
None; if stringized, it will be the empty string (''):
Example 53: Significators, optional values
Source: ⌨️
@%none
@%!empty
This is a None: @repr(__none__).
This is an empty string: @repr(__empty__).
Output: 🖥️
This is a None: None.
This is an empty string: ''.
Hint
Significators can appear anywhere in an EmPy document, but typically are used at the beginning.
Tip
A compiled regular expression object is returned by the
significatorRe configuration method and can be used to
systematically find all the significators in a given text.
The values of a non-stringinized significators can be any Python expression, so can include side effects from prior EmPy expansions. It’s best practice, however, to only have significator values depend on the value of previous significators, so that trimmed down processors can evaluate them without having to expand the entire document.
New in version 1.2: Significator markup was introduced in EmPy version 1.2. Stringified and multiline variants were introduced in version 4.0.
Context markups#
Contexts are objects which track the current progress of an EmPy interpreter through its source document(s) for the purposes of error reporting. This is handled automatically by the EmPy system, but they can be modified through the API or with context markup.
New in version 3.0.2: Context markups were introduced in EmPy version 3.0.2.
Context name markup: @?... NL#
The context name markup can be used to change the current context
name with @?... NL; it uses as the new name what follows on the
same line and consumes everything up to and including the newline.
Whitespace surrounding the context name is ignored.
Example 54: Context names
Source: ⌨️
@?Test
This context is now: @empy.getContext().
Output: 🖥️
This context is now: Test:2:22.
Context line markup: @!... NL#
The context line markup can be used to change the current context
line with @!... NL; it uses as the new line what follows on the
same line and consumes everything up to and including the newline.
Whitespace surrounding the context name is ignored. If the remaining
text is not parseable as an integer, it is a parse error.
Example 55: Context lines
Source: ⌨️
@!1000
This context is now: @empy.getContext().
Note that the line is 1001 since it's the next line after the markup.
Output: 🖥️
This context is now: <example 55 "Context lines">:1001:22.
Note that the line is 1001 since it's the next line after the markup.
Extension markup: @((...)), @[[...]], @{{...}}, @<...>, …#
Markup can be provided with customizable user-defined meanings with extension markup. Use of these markups calls a method on an extension instance installed with the running interpreter, and serializes its return result. Once installed, an extension cannot be uninstalled (but you can dynamically change its behavior). Each of these methods has the following signature:
method(contents: str, depth: int, locals: Optional[dict]) -> str
It takes the following arguments:
Argument |
Type |
Description |
|---|---|---|
|
|
The contents inside the markup |
|
|
The number of opening and closing markup characters |
|
|
The locals dictionary or |
The return value is a string to serialize to the output. Of course, these methods can perform any other desired side effects. Encountering extension markup with no installed extension, or with an extension that has no correspondingly defined method is an error.
The following extension markups are available out of the box:
Markup |
Start |
Extension method name |
Minimum depth |
|---|---|---|---|
|
|
|
2 |
|
|
|
2 |
|
|
|
2 |
|
|
|
1 |
Extension markup is parsed so that the number of starting and ending
characters can be of any depth but the number of starting and ending
characters must match. For angle brackets extension markup, any depth
can be used. For the others, a depth of 2 or more is needed (since
only one character, e.g., @(...), is a different markup). For
additional user-specified markups, it is up to the user.
Example 56: Extensions
Source: ⌨️
@{
import em
class Extension(em.Extension):
def parentheses(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('parentheses', contents, depth)
def square_brackets(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('square_brackets', contents, depth)
def curly_braces(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('curly_braces', contents, depth)
def angle_brackets(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('angle_brackets', contents, depth)
empy.installExtension(Extension())
}@
Parentheses: @((This is a test.))
Parentheses: @(((This is a test.)))
Parentheses: @((((This is a test.))))
Square brackets: @[[This is a test.]]
Square brackets: @[[[This is a test.]]]
Square brackets: @[[[[This is a test.]]]]
Curly braces: @{{This is a test.}}
Curly braces: @{{{This is a test.}}}
Curly braces: @{{{{This is a test.}}}}
Angle brackets: @<This is a test.>
Angle brackets: @<<This is a test.>>
Angle brackets: @<<<This is a test.>>>
Angle brackets: @<<<<This is a test.>>>>
Output: 🖥️
Parentheses: [parentheses] "This is a test." (depth 2)
Parentheses: [parentheses] "This is a test." (depth 3)
Parentheses: [parentheses] "This is a test." (depth 4)
Square brackets: [square_brackets] "This is a test." (depth 2)
Square brackets: [square_brackets] "This is a test." (depth 3)
Square brackets: [square_brackets] "This is a test." (depth 4)
Curly braces: [curly_braces] "This is a test." (depth 2)
Curly braces: [curly_braces] "This is a test." (depth 3)
Curly braces: [curly_braces] "This is a test." (depth 4)
Angle brackets: [angle_brackets] "This is a test." (depth 1)
Angle brackets: [angle_brackets] "This is a test." (depth 2)
Angle brackets: [angle_brackets] "This is a test." (depth 3)
Angle brackets: [angle_brackets] "This is a test." (depth 4)
Extensions can be used to define entirely new markup in this way. The
first optional argument to the Extension constructor is a dict or
list or 2-tuples mapping first characters to method names. If it is a
list, it will be added to the default mapping:
Example 57: Extensions, additions
Source: ⌨️
@{
import em
class Extension(em.Extension):
def __init__(self):
super().__init__([('/', 'slashes')])
def parentheses(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('parentheses', contents, depth)
def square_brackets(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('square_brackets', contents, depth)
def curly_braces(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('curly_braces', contents, depth)
def angle_brackets(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('angle_brackets', contents, depth)
def slashes(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('slashes', contents, depth)
empy.installExtension(Extension())
}@
Parentheses: @((This is a test.))
Square brackets: @[[This is a test.]]
Curly braces: @{{This is a test.}}
Angle brackets: @<This is a test.>
Slashes: @/This is a test./
Slashes: @//This is a test.//
Slashes: @///This is a test.///
Slashes: @////This is a test.////
Output: 🖥️
Parentheses: [parentheses] "This is a test." (depth 2)
Square brackets: [square_brackets] "This is a test." (depth 2)
Curly braces: [curly_braces] "This is a test." (depth 2)
Angle brackets: [angle_brackets] "This is a test." (depth 1)
Slashes: [slashes] "This is a test." (depth 1)
Slashes: [slashes] "This is a test." (depth 2)
Slashes: [slashes] "This is a test." (depth 3)
Slashes: [slashes] "This is a test." (depth 4)
Warning
If the opening and closing characters are the same, the markup must
contain at least one other character in order to be recognized. For
instance, if an extension is added for @/.../, the character
sequence @// is not an extension markup with a depth of one
containing the empty string; it is the unfinished start of an
extension markup of at least depth two. @/ /, with a space in
between, on the other hand, would be valid.
The first constructor argument can also be a dict, in which case the mapping is completely replaced:
Example 58: Extensions, replacement
Source: ⌨️
@{
import em
class Extension(em.Extension):
def __init__(self):
super().__init__({
'((': 'parens',
'[[': 'brackets',
'{{': 'braces',
'<': 'angles',
'/': 'slashes',
})
def parens(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('parens', contents, depth)
def brackets(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('brackets', contents, depth)
def braces(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('braces', contents, depth)
def angles(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('angles', contents, depth)
def slashes(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('slashes', contents, depth)
empy.installExtension(Extension())
}@
Parentheses: @((This is a test.))
Square brackets: @[[This is a test.]]
Curly braces: @[[This is a test.]]
Angle brackets: @<This is a test.>
Slashes: @/This is a test./
Output: 🖥️
Parentheses: [parens] "This is a test." (depth 2)
Square brackets: [brackets] "This is a test." (depth 2)
Curly braces: [brackets] "This is a test." (depth 2)
Angle brackets: [angles] "This is a test." (depth 1)
Slashes: [slashes] "This is a test." (depth 1)
Note that the markup opening can either be one character or two. This
is so that some extension markup can exist alongside of existing
markup (e.g., @((...)) is extension markup whereas @(...) is
expression markup).
Finally, you can manually install token class factories corresponding to your extension:
Example 59: Extensions, manual
Source: ⌨️
@{
import em
class Extension(em.Extension):
def __init__(self):
super().__init__({})
def the_colons(self, contents, depth, locals):
return '[{}] "{}" (depth {})'.format('the_colons', contents, depth)
empy.installExtension(Extension())
factory = empy.config.getFactory()
factory.addToken(empy.config.createExtensionToken(';', 'the_colons', ':'))
}@
The colons: @;This is a test.:
Output: 🖥️
The colons: [the_colons] "This is a test." (depth 1)
Attention
Note that when markup which has starting and ending delimiters appears
alone on a line, the trailing newline will be rendered in the output.
To avoid these extra newlines, use a trailing @ to turn it
into whitespace markup which consumes that trailing newline, so e.g.
@<...> followed by
a newline becomes @<...>@ followed by a newline. This is idiomatic for
suppressing unwanted newlines. See here for more details.
New in version 4.1: Extension markup was introduced in EmPy version 4.1.
Features#
Various additional features are available in a running EmPy system. The following subsections list the various features available in the EmPy system and in which version they were introduced.
Feature |
Description |
Ver. |
|---|---|---|
The pseudomodule/interpreter available in an EmPy system |
1.0 |
|
Preprocessing and postprocessing commands |
1.x |
|
Plugins for the interpreter |
4.1 |
|
Alternatives for the underlying language interpreter |
4.1 |
|
Specify user-customizable markup |
4.1 |
|
Specify user-customizable markup for |
3.3 |
|
Functions to be called on interpreter shutdown |
2.1 |
|
Defer and playing back output |
1.0 |
|
Filter output |
1.3 |
|
Import native EmPy modules |
4.2 |
|
Inspect and modify interpreter behavior |
2.0–4.0 |
Pseudomodule/interpreter#
The pseudomodule/interpreter can be accessed by a running EmPy system by
referencing its name (which defaults to
empy) in the globals:
Example 2: Pseudomodule sample
Source: ⌨️
This version of EmPy is @empy.version.
The prefix in this interpreter is @empy.getPrefix() @
and the pseudomodule name is @empy.config.pseudomoduleName.
Do an explicit write: @empy.write("Hello, world!").
The context is currently @empy.getContext().
Adding a new global in a weird way: @
@empy.updateGlobals({'q': 789})@
Now q is @q!
You can do explicit expansions: @empy.expand("1 + 1 = @(1 + 1)").
q is @(empy.defined('q') ? 'defined' ! 'undefined').
Output: 🖥️
This version of EmPy is 4.2.1.
The prefix in this interpreter is @ and the pseudomodule name is empy.
Do an explicit write: Hello, world!.
The context is currently <example 2 "Pseudomodule sample">:5:26.
Adding a new global in a weird way: Now q is 789!
You can do explicit expansions: 1 + 1 = 2.
q is defined.
Important
The pseudomodule and interpreter are one and the same object; the
terms pseudomodule and interpreter are used interchangeably. The
interpreter exposes itself as the pseudomodule
empy in a running EmPy system; this
pseudomodule is never imported explicitly.
New in version 1.0: The pseudomodule was introduced in EmPy version 1.0.
Interpreter attributes and methods#
Interpreter attributes#
The following attributes are set on the pseudomodule after it is initialized.
version: strThe version of EmPy.
compat: list[str]A list of strings indicating the “compatibility features” that were automatically enabled to support or call out earlier versions of Python. Possible strings are:
Feature
Description
Affected versions
BaseExceptionBaseExceptionclass does not existbefore 2.5
FileNotFoundErrorFileNotFoundErrorclass does not existbefore 3.3
callablecallablebuiltin does not existfrom 3.0 up to 3.2
chr/decodeSubstituted an implementation of
chrfor narrow Unicode builds usingdecodebefore 3.0
chr/uliteralSubstituted an implementation of
chrfor narrow Unicode builds usinguliteralbefore 2.6
narrowPython was built with narrow Unicode (strings natively stored as UCS-2)
—
!modulesEmPy module support disabled;
importlibnot available (or IronPython)before 3.4
!codecs.opencodecs.openis deprecated (useopeninstead)3.14 and up
Note
Whether Python builds are narrow is a function of how the Python interpreter was built, and not directly correlated with the Python version.
executable: strThe path to the EmPy interpreter that is being used by the system (analogous to
sys.executable).argv: list[str]The arguments (analogous to
sys.argv) used to start the interpreter. The first element is the EmPy document filename and the remaining elements are the arguments, if any. If no EmPy document was specified,<->is used.config: ConfigurationThe configuration instance that the interpreter is using.
core: CoreThe core used by this interpreter.
extension: Optional[Extension]The extension, if any, used by this interpreter.
enabled: boolA Boolean indicating whether or not output is currently enabled. This can be disabled and re-enabled with switch markup.
ok: boolA Boolean indicating whether or not the interpreter is still active.
error: Optional[Error]If an error occurs, the instance of it will be assigned to this attribute. When using
invoke, this will determine whether or not a failure exit code is returned. No error is indicated byNone.
Interpreter constructor#
__init__(**kwargs)The constructor. It takes the following keyword arguments (listed in alphabetical order), all of which have reasonable defaults.
Argument
Type
Meaning
Default
argvSequence[str]The system arguments to use
['<->']callbackCallableA custom callback to register [deprecated]
NoneconfigConfgurationThe configuration instance to use
default
coreCoreThe interpreter core to use
Core()dispatcherbool | CallableDispatch errors or raise to caller?
TrueexecutablestrThe path to the EmPy executable
".../em.py"extensionExtensionThe extension to install on this interpreter
NonefilespectupleA 3-tuple of the input filename, output mode, and buffering
NonefiltersSequence[Filter]The list of filters to install
[]finalizersSequence[Callable]The list of finalizers to install
[]globalsdictThe globals dictionary to use
{}handlerCallableThe error handler to use
default
hooksSequence[Hook]The list of hooks to install
[]identstrThe identifier of the interpreter (used for debugging)
NoneimmediatelyboolDeclare the interpreter ready immediately after initialization?
TrueinputfileThe input file to use for interactivity
sys.stdinoriginboolIs this the top-level interpreter?
FalseoutputfileThe output file to use
sys.stdoutrootstr | tuple | ContextThe root interpreter context filename
'<root>'The ordering of the arguments does not matter. Missing arguments have reasonable defaults and unrecognized arguments are ignored.
Important
The order of the
Interpreterconstructor arguments has changed over time and is subject to change in the future, so you must use keyword arguments to prevent any ambiguity, e.g.:import em myConfig = em.Configuration(...) myGlobals = {...} myOutput = open(...) interp = em.Interpreter( config=myConfig, globals=myGlobals, output=myOutput, ...)
The allowed arguments are:
argv: Optional[Sequence[str]]The list of EmPy arguments. The first element is always the EmPy executable, with the remaining elements the actual arguments. If not specified, a reasonable default is used with no arguments.
callback: Optional[Callable]The custom callback to register. Defaults to no callback.
Warning
Custom callbacks are deprecated in favor of extensions but registering them is supported for backward compatibility providing that extensions are not also being used.
config: Optional[Configuration]The configuration to use for this interpreter. If not specified, a default configuration will be created and used.
Note
The current configuration of an interpreter can be modified while the interpreter is running and the changes will be effective as they occur. Configurations can also be shared between multiple interpreters if desired.
core: CoreThe core to use with this interpreter. See Cores for more information.
dispatcher: bool | CallableThe dispatcher to use when an error is encountered. Dispatchers determine whether the error handler will be called (
True), whether the error will be reraised to the caller (False), or something else (a custom callable). See Error dispatchers for more information.executable: strA string representing the path to the EmPy executable.
extension: Optional[Extension]The extension to install, if any.
filespec: Optional[tuple[str, str, int | str]]An optional 3-tuple of the filename, the file open mode, and the buffering mode of the EmPy script to be loaded. When using the command line arguments, this will be handled automatically.
filters: Sequence[Filter]A list of filters to install at startup. Defaults to none.
finalizers: Sequence[Callable]A list of finalizers to install at startup. Defaults to none.
globals: Optional[dict]The globals dictionary to use for this interpreter. If not specified, an empty dictionary will be created and used.
handler: Optional[Callable]The error handler to set. If not specified, use the default handler.
hooks: Sequence[Hook]A list of hooks to install at startup. Defaults to none.
ident: Optional[str]The name of the interpreter, printed when calling
repron the interpreter/pseudomodule object. Used only for debugging; defaults toNone.immediately: boolA Boolean which indicates whether or not the
readymethod will be called before the constructor exits. This is only relevant for hooks which implement theatReadymethod. Defaults to true.input: Optional[file]The input file to use for interactive mode and pausing at end. Defaults to
sys.stdin.origin: boolIs this the top-level interpreter? This is used to determine whether to report an error if the proxy is not properly cleaned up on its shutdown, suggesting that the proxy reference count got out of sync due to a subinterpreter not being properly shutdown. Defaults to
Falsefor a new interpreter, but calling the globalinvokefunction (as the main em.py executable does) sets it toTruefor the main interpreter.output: Optional[file]The output file to use. Defaults to
sys.stdout.root: str | (tuple[str] | tuple[str, int] | tuple[str, int, int]) | ContextThe root context to use, which appears at the bottom of every Python error traceback (
-r/--raw-errors). This can be a string, representing the filename; a tuple with between 1 and 3 parameters, with the full 3-tuple consisting of the name, the line number, and the column number; or an instance of theContextclass, which will be cloned.
Warning
The five
...Funcarguments (evalFunc,execFunc,definerFunc,matcherFuncandserializerFunc) collectively define the behavior of the underlying interpreter (which defaults to Python). Alternates can be specified if desired; however, specifying these arguments in the constructor in this way is now deprecated. (These arguments to the constructor are still supported for backward compatibility, however.) Instead, use cores. Using cores is as simple as passing the functions (which, if not specified, will default to the standard Python interpreter) to aCoreconstructor and using that:import em core = em.Core( evaluate=evalFunc, execute=execFunc, serialize=serializerFunc, define=definerFunc, match=matcherFunc, ) interp = em.Interpreter(core=core, ...)
See also
The list of
Interpreterconstructor arguments is available in theconstructorhelp topic and is summarized here.
Interpreter methods#
These methods involve the interpreter directly.
Note
Most interpreter methods return None so they can be called from
EmPy expression markup.
__enter__()/__exit__(*exc)The interpreter presents a context manager interface and so can be used with the
withPython control structure; this will automatically shut down the interpreter after the control structure ends, e.g.:import em with em.Interpreter(...) as interp: ... manipulate interp here ... # interp is now shutdown
reset([clearStacks: bool])Reset the interpreter to a pristine state. If
clearStacksis true, reset the stacks as well.
ready()Declare the interpreter ready for processing. This calls the
atReadyhook. By default this is called before the constructor exits, but the user can do this explicitly by passingFalseto theimmediatelyconstructor argument and calling it when they wish to declare the interpreter ready.
shutdown()Shutdown the interpreter. No further expansion must be done. This method is idempotent.
Important
When you create an interpreter, you must call its
shutdownmethod when you are done. This is required to remove the proxy onsys.stdoutthat EmPy requires for proper operation and restore your Python environment to the state it was before creating the interpreter. This can be accomplished by creating the interpreter in awithstatement — interpreters are also context managers — or by creating it and shutting it down in atry/finallystatement.This is not needed when calling the
expandglobal function; it creates and shuts down an ephemeral interpreter automatically.
Interpreter file-like methods#
These methods mimic a file so the interpreter can be treated as a
file-like object (e.g., print("Lorem ipsum", file=empy).
write(data: str)Write the string data to the output stream.
writelines(lines: list[str])Write the sequence of strings to the output stream.
flush()Flush the output stream.
close()Close the output stream. Note this will never close the fundamental output stream; it will only flush it, and it will only close other streams when they are not at the bottom of the stream stack.
serialize(thing: object)Write a string version of the object to the output stream. This will reference
--none-symbol(configuration variable:noneSymbol) if the object isNone.
Interpreter stream methods#
top() -> StreamGet the top-level stream.
push()Push this interpreter onto the proxy’s stream stack.
pop()Pop this interpreter off the proxy’s stream stack.
clear()Clear the interpreter’s stacks.
Interpreter high-level methods#
go(inputFilename, inputMode, [preprocessing, [postprocessing]])Process the main document with the given mode. Optionally process the specified commands before processing the main document and after, respectively.
interact()Go into interactive mode.
file(file, [locals, [dispatcher]])Process the given file, expanding its contents. This will defer to one of the below methods based on the buffering setting.
fileLines(file, [locals, [dispatcher]])Process the given file line by line.
fileChunks(file, [bufferSize, [locals, [dispatcher]]])Process the given file in chunks with the optional buffer size; if not specified, the configuration default will be used.
fileFull(file, [locals, [dispatcher]])Process the given file as a single chunk that’s read in all at once.
string(string, [locals, [dispatcher]])Process the given string, expanding its contents.
import_(filename, module, [locals, [dispatcher]])Import an EmPy module contained in
filenameto the module objectmodule.process(command: Command)Process a command.
processAll(commands: Sequence[Command])Process a sequence of commands.
Interpreter context methods#
These methods manipulate the interpreter’s context stack.
identify() -> tuple[char, int, int, int]Get a 4-tuple of the current context, consisting of the filename, the line number, the column number, and the number of characters (Unicode code points) processed.
getContext() -> ContextGet the current context object.
newContext([name: str, [line: int, [column: int, [chars: int]]]]) -> ContextCreate a new context and return it.
pushContext(context: str | tuple | Context)Push the given context on top of the context stack.
popContext()Pop the top context off the context stack; do not return it.
setContext(context: str | tuple | Context)Replace the context on the top of the context stack with the given context.
setContextName(name: str)Set the top context’s name to the given value.
setContextLine(line: int)Set the top context’s line to the given value.
setContextColumn(column: int)Set the top context’s column to the given value.
setContextData([name: str, [line: int, [column: int, [chars: int]]]])Set the top context’s name, line, and/or column to the given value(s).
restoreContext(oldContext: str | tuple | Context)Restore the top context on the stack to the given context.
Interpreter finalizer methods#
These methods manipulate the interpreter’s finalizers.
clearFinalizers()Clear all finalizers from this interpreter.
appendFinalizer(finalizer: Callable)/atExit(finalizer: Callable)Append the given finalizer to the finalizers list for this interpreter.
atExitis an alias for backward compatibility [deprecated].prependFinalizer(finalizer: Callable)Prepend the given finalizer to the finalizers list for this interpreter.
setFinalizers(finalizers: list[Callable])Replace the current list of finalizers wih the given sequence.
Interpreter globals methods#
These methods manipulate the interpreter’s globals.
getGlobals() -> dictGet the current globals dictionary.
setGlobals(globals: dict)Set the current globals dictionary,.
updateGlobals(moreGlobals: dict)Update the current globals dictionary, adding this dictionary’s entries to it.
clearGlobals()Clear the current globals dictionary completely.
saveGlobals([deep: bool])Save a copy of the globals off to on the history stack. If deep is true, do a deep copy (defaults to false).
restoreGlobals([destructive: bool])Restore the globals dictionary on the top of the globals history stack. If destructive is true (default), pop it off when done.
flattenGlobals([skipKeys: Sequence[str]])Flatten the interpreter namespace into the globals. If
skipKeysis specified, skip over those keys; otherwise, use the defaults from the configuration.
Interpreter expansion methods#
These methods are involved with markup expansion.
include(fileOrFilename, [locals, [name]])Include the given EmPy (not Python) document (or filename, which is opened) and process it with the given optional locals dictionary and context name.
expand(data, [locals, [name], [dispatcher]]) -> strCreate a new context and stream to evaluate the EmPy data, with the given optional locals and context name and return the result. If the expansion raises an exception, by default it will be raised up to the caller; set
dispatcherto true to have the interpreter handle it with its formal error handler mechanism. Setdispatcherto another callable to do custom dispatching. See Error dispatchers for more information.defined(name, [locals]) -> boolReturn a Boolean indicating whether the given name is present in the interpreter globals (or the optional locals, if provided).
lookup(name, [locals]) -> objectLookup the value of a name in the globals (and optionally the locals, if provided) and return the value.
evaluate(expression, [locals, [write]]) -> objectEvaluate the given Python expression in the interpreter, with the given optional locals dictionary. If write is true, write it to the output stream, otherwise return it (defaults to false).
execute(statements, [locals])Execute the given Python statements in the interpreter, with the given optional locals dictionary.
single(source, [locals]) -> Optional[object]Execute the given Python expression or statement, with the given optional locals dictionary. This compiles the code with the
singlePython compilation mode which supports either. Return the result orNone. This method is not used internally by the EmPy system and is not used by interpreter cores but is available for embedding.atomic(name, value, [locals])Do an atomic assignment of the given name and value in the interpreter globals. If the optional locals dictionary is provided, set it in the locals instead.
assign(name, value, [locals])Do a potentially complex assignment of the given name “lvalue” and “rvalue.” Unlike
atomic,assigncan support tuple assignment.significate(key, [value, [locals]])Declare a significator with the given key and optional value (if not specified, defaults to
None). If the optional locals dictionary is provided, set it in the locals instead.quote(string) -> strGiven an EmPy string, return it quoted.
escape(string) -> strGiven an EmPy string, escape non-ASCII characters in it and return.
getPrefix() -> strGet this interpreter’s prefix.
setPrefix(char)Set this interpreter’s prefix.
Interpreter diversion methods#
These methods manipulate the interpreter’s diversions.
stopDiverting()Stop any current diversion.
createDiversion(name)Create a new diversion with the given name but do not start diverting to it.
retrieveDiversion(name, [default]) -> DiversionGet the diversion with the given name. If
defaultis provided, return that if the diversion does not exist; otherwise, raise an error.startDiversion(name)Start diverting to a diversion with the given name, creating if it necessary.
playDiversion(name, [drop])Play the diversion with the given name, optionally dropping it (default is true).
replayDiversion(name, [drop])Play the diversion with the given name, optionally dropping it (default is false).
dropDiversion(name)Drop the diversion with the given name without playing it.
playAllDiversions()Play all diversions in sorted order by name, dropping them.
replayAllDiversions()Replay all diversions in sorted order by name, leaving them in place.
dropAllDiversions()Drop all diversions without playing them.
getCurrentDiversionName() -> Optional[str]Get the name of the current diversion or
Noneif there is no current diversion.getAllDiversionNames() -> list[str]Get a list of the names of all diversions in sorted order.
isExistingDiversionName(name) -> boolIs the given name the name of an existing diversion?
Interpreter filter methods#
These methods manipulate the interpreter’s filters.
resetFilter()Reset the filtering system so there are no filters.
getFilter() -> FilterGet the top-most filter.
getLastFilter() -> FilterGet the bottom-most filter.
setFilter(*filters)Set the top-most filter(s) to the given filter chain, replacing any current chain. More than one filter can be specified as separate arguments.
prependFilter(filter)Prepend the given filter to the current filter chain.
appendFilter(filter)Append the given filter to the current filter chain.
setFilterChain(filters)Set the filter chain to the given list of filters, replacing any current chain.
Interpreter core methods#
These methods involve cores, an optional EmPy feature for overriding the core behavior of an EmPy interpreter. See cores for details.
hasCore() -> boolDoes this interpreter currently have a core installed? (A default core is installed by the time initialization ends, regardless of whether or not a custom core has been specified.)
getCore() -> CoreGet the core currently inserted into this interpreter.
insertCore(core: Optional[Core])Insert a core on this interpreter. If
coreisNone, a default core will be created and used. This will detach any previous core.ejectCore()Eject this interpreter’s core. Since cores may have a reference back to the interpreter, this will cut any cyclical link that may be present. This method is automatically called by the interpreter’s
shutdownmethod. Note that once this method is called, no further expansion can be performed by this interpreter until a new core is installed. This method is idempotent.resetCore()Reset the core for this interpreter to the default (Python).
Interpreter extension methods#
hasExtension() -> boolDoes this interpreter already have an extension installed?
getExtension() -> Optional[Extension]Get the extension installed in this interpreter, or
Noneif there is no such extension.installExtension(Extension)Install an extension in this interpreter. This can only be done once per interpreter.
callExtension(name: str, contents: str, depth: int)Calls the extension as if extension markup had been encountered and serializes the result.
Interpreter hook methods#
These methods manipulate the interpreter’s hooks.
invokeHook(_name: str, **kwargs)Invoke the hooks associated with the given name and keyword arguments dictionary. This is the primary method called when hook events are invoked.
areHooksEnabled() -> boolAre hooks currently enabled?
enableHooks()Enable hooks.
disableHooks()Disable hooks. Any existing hooks will not be called until
enableHooksis called.getHooks() -> list[Hook]Get the current list of hooks.
prependHook(hook: Hook)Prepend the given hook to the list of hooks.
appendHook(hook: Hook)Append the given hook to the list of hooks.
removeHook(hook: Hook)Remove the given hook from the list of hooks.
clearHooks()Clear the list of hooks.
Interpreter callback methods#
These methods manipulate the interpreter’s custom callback. A callback is a callable object which takes one argument: the content to process.
hasCallback() -> boolDoes this interpreter have a custom callback registered?
getCallback() -> Optional[Callable]Return the interpreter’s registered custom callback or
Noneif none is registered.registerCallback(callback)Register the given callback with the interpreter, replacing any existing callback.
deregisterCallback()Remove the current interpreter’s registered callback, if any.
invokeCallback(contents)Manually invoke the interpreter’s custom callback as if the custom markup
@<...>were expanded.
Warning
Custom callbacks are deprecated in favor of extensions but registering them and querying them is supported for backward compatibility, providing that extensions are not also being used.
Interpreter error handler methods#
These methods manipulate the interpreter’s error handler. A handler is a callable object which takes three arguments: the type of the error, the error instance itself, and a traceback object.
defaultHandler(type, error, traceback)The default EmPy error handler. This can be called manually by custom error handlers if desired.
getHandler() -> CallableGet the current error handler, or
Nonefor the default.setHandler(handler, [exitOnError])Set the error handler. If
exitOnErroris notNone(defaults to false), also set the interpreter’s configuration’sexitOnErrorconfiguration variable. This default isFalse(so that custom error handlers do not automatically exit, which is usually the intent).resetHandler([exitOnError])Reset the error handler to the default.
exitOnErroris as above.invokeHandler(*exc)Manually invoke the error handler. The arguments should be the 3-tuple of the return value of
sys.exc_infoas a single argument or as three positional arguments, e.g.:interp.invokeHandler(sys.exc_info()) # or: *sys.exc_info()
getExitCode() -> intGet the exit code that will be returned by the process given the current state of the
errorattribute.
Interpreter emoji methods#
initializeEmojiModules([moduleNames: Sequence[str]])Initialize the allowed emoji modules to use by name. If the names list is not specified, use the defaults.
getEmojiModule(moduleName: str) -> ModuleGet the initialized module abstraction corresponding to the given module name.
getEmojiModuleNames() -> list[str]Return the list of available emoji modules by name in their proper order.
substituteEmoji(text: str) -> strUse the emoji facilities to lookup the given emoji name and return the result as if the emoji markup
@:...:were expanded.
See also
The list of pseudomodule/interpreter attributes in methods is
available in the pseudo help topic and is summarized
here.
Commands#
Commands are self-contained objects which encapsulate some interpreter processing. They are primarily used by the command line options system, but can be used by users.
Commands are created from the Command class and its subclasses, and
are processed by an interpreter with its process method. Commands
are created with a single argument which represents the action of that
particular command. For instance, this EmPy code will use commands to
include an EmPy document:
Example 60: Commands
Source: ⌨️
@{
import em
# Create a temporary file for this example.
with open('/tmp/include.em', 'w') as file:
file.write("Hello, world! 1 + 1 = @(1 + 1).\n")
}@
Including a file with a command:
@empy.process(em.DocumentCommand('/tmp/include.em'))@
Output: 🖥️
Including a file with a command:
Hello, world! 1 + 1 = 2.
A sequence of commands can be processed with the processAll method.
The following Command subclasses are available, alongside their
corresponding command line options. Preprocessing commands are
processed before the main EmPy document is expanded; postprocessing
commands after.
Subclass |
Behavior |
Preprocessing option |
Postprocessing option |
|---|---|---|---|
|
Import a Python module |
|
|
|
Define a Python variable |
|
|
|
Define a Python string variable |
|
|
|
Expand an EmPy document by filename |
|
|
|
Execute a Python statement |
|
|
|
Execute a Python file by filename |
|
|
|
Expand some EmPy markup |
|
|
Users can define their own subclasses of Command.
See also
For more details on the various commands, check the corresponding Command line options.
Changed in version 4.0: Commands were codified and introduced in EmPy version 4.0, though the equivalent command line options that they correspond to were available going back to 1.x.
Plugins#
Plugins are objects which can be installed in an interpreter and
contain a reference back to it via an interp attribute. They are
registered with the interpreter by calling an interpreter method such
as insertCore, installExtension, etc. and are either callable
objects (callbacks, finalizers) or are objects defined with attributes
approrpiate to their purpose (cores, extensions). User-defined
plugins can derive from em.Plugin or the relevant subclass (e.g.,
em.Core or em.Extension).
The types of plugins available follow below.
Type |
Purpose |
Subclass |
Install, uninstall method |
Ver. |
|---|---|---|---|---|
Modify core interpreter behavior |
|
|
4.1 |
|
Add additional customized markup |
|
|
4.1 |
|
Add custom markup callback (deprecated) |
|
|
3.3 |
|
Functions to call before shutdown |
|
|
2.1 |
|
Objects to adjust interepter behavior by event |
|
|
2.0 |
|
Error handlers |
|
|
4.0 |
New in version 4.1: Plugins were codified and introduced in EmPy version 4.1.
Cores#
By default, of course, EmPy expands expressions and statements through the underlying Python interpreter. But even this behavior is configurable with interpreter cores. Cores can be used to completely change the underlying language that EmPy expands to (provided, naturally, that it can be implemented with Python).
Cores (represented with the base class Core in the module em)
support any language/system that can be encapsulated with a set of
globals, optional locals, and with these actions (methods on the core
object): evaluating an expression, executing a statement, serializing
an object, defining an EmPy function (@[def]), and defining the
behavior of the @[match] markup.
As with the Python languge, expressions which are evaluated must
return a value (or None); statements which are executed do not
return a value. Beyond this definition, the meaning and purpose of
these operations in a custom core are completely configurable.
Cores can be created by either providing a set of callables to the
Core constructor or by deriving a subclass from Core and providing
overriding methods. The default implementation (Core()) provides
the implementation for Python. Not specifying a core defaults to this
implementation.
The default Core class has the following constructor:
__init__(**kwargs)Create a core with optional keyword arguments. The arguments can be callables representing the different possible operations on a core, or an interpreter to attach to immediately after initialization:
Argument
Description
Default
evaluateEvaluate an expression; return the result
evalexecuteExecute a statement; no return result
execserializeSerialize an object; return the result
strdefineFunctionality of
@[def ...]markup; no return result(Python-specific)
matchFunctionality of
@[match ...]markup; no return result(Python-specific)
An optional
interpargument is also allowed which will automatically attach this core to the given interpreter after intiialization.
The expected signatures of these methods are as follows:
evaluate(code: str, globals: dict, [locals: dict]) -> objectEvaluate the string expression given the current globals (and optional locals) and return the result.
execute(code: str, globals: dict, [locals: dict])Execute the string statements given the current globals (and optional locals). The return value is ignored.
serialize(thing: object) -> strTake a custom object and render it as a string for output.
define(signature: str, definition: str, [globals: dict, [locals: dict]])Implement the behavior of the
defcontrol markup@[def SIGNATURE]DEFINITION@[end def], given the globals dictionary (defaults to the interpreter’s globals), and an optional locals dictionary. The meaning of the signature and the definition are arbitrary. The return value is ignored.match(expression: str, cases: list[Core.Case], [locals: dict])Implement the behavior of the
matchcontrol markup@[match EXPRESSION]...@[end match]. The first argument is the string expression to test.casesis a list ofCore.Caseinstances each representing acasestatements. Cases have the following attributes:Attribute
Type
Purpose
expressionstrA string representing the case test expression
tokenslist[Token]The list of tokens to run if there is a match
The
expressioninstance is the string representing the case test, and the second element is a list ofCore.Caseinstances representing the case expression to test and the markup to expand when the case matches. Also passed are is an optional locals dictionary. The return result is ignored.
Cores are installed in an interpreter by either providing one as the
core constructor argument or by calling
the insertCore interpreter method. An interpreter’s core can be
reset to the default (Python implementation core) with the resetCore
method, or can be manually removed by calling the ejectCore method
(though this will leave the interpeter non-functional until a new core
is installed). An interpreter’s core can also be modified dynamically
while an interpreter is running.
Cores must be attached to the interpreter in order to make sure that
cores have a reference to the interpreter (needed for the default
define method). This is done automatically when calling
insertCore.
As mentioned earlier, cores can be created in one of two ways. First,
a subclass of Core in the em module can be instantiated and
provided to the interpreter:
import em
class MyCore(em.Core):
def evaluate(self, code, globals, locals=None): ...
def execute(self, code, globals, locals=None): ...
def serialize(self, thing): ...
def define(self, signature, definition, globals, locals=None): ...
def match(self, expression, casePairs, globals, locals=None): ...
core = MyCore(...)
interp = em.Interpreter(core=core)
Alternatively, the core methods can be implemented as standalone
callables and passed to the Core constructor:
import em
def myEvaluate(code, globals, locals=None): ...
def myExecute(code, globals, locals=None): ...
def mySerialize(thing): ...
def myDefine(signature, definition, globals, locals=None): ...
def myMatch(expression, casePairs, globals, locals=None): ...
core = em.Core(
evaluate=myEvaluate,
execute=myExecute,
serialize=mySerialize,
define=myDefine,
match=myMatch,
)
interp = em.Interpreter(core=core)
For methods which are not defined in a subclass or specified as a callable in the constructor, the default (Python implementation core) will be used. The source code for the default definitions can be used as a guide.
Tip
The define method and match method correspond to the @[def ...]
and @[match ...] markup, respectively. If these markups will not
be used by the user, these methods can be left unimplemented as they
will never be called. It’s good form, however, to have them raise
NotImplementedError in that case just to make the intent clear.
New in version 4.1: Interpreter cores were introduced in EmPy version 4.1.
Extensions#
Starting with EmPy 4.1, users can now specify their own customizable
markup with extensions. They define methods which are called when
the respective custom markup is expanded and are installed via the
installExtension method on the interpreter.
Extensions are documented in the Extension markup section.
New in version 4.1: Extensions were introduced in EmPy version 4.1, replacing custom markup which was introduced in EmPy version 3.3.
Callbacks#
Warning
Custom callbacks are deprecated in favor of extensions but registering them and querying them is supported for backward compatibility providing that extensions are not also being used.
Before the introduction of extensions, only one markup
was available for customization: the custom markup, @<...>.
This meaning of this markup was provided with the use of a Python
callable object referred to as a custom callback, or just
“callback,” which can be set or queried using pseudomodule functions.
At most one custom callback can be registered, and once registered, it
cannot be deregistered or replaced.
When the custom markup @<...> is encountered, the contents inside
the markup are passed to the current custom callback. Its return
value, if not None, is then written to the output stream. The
custom callback may also perform operations with side effects
resulting in output, as well. If there are multiple opening angle
brackets, an equal number of closing angle brackets will be required
to match. This allows the embedding of < and > in the contents
passed to the callback.
The custom callback is a callable object which, when invoked, is
passed a single argument: a string representing the contents of what
was found inside the custom markup @<...>. Only one custom
callback can be registered at a time.
To register a callback, call empy.registerCallback. To see if there
is a callback registered, use empy.hasCallback. To retrieve the
callback registered with the interpreter, use empy.getCallback; if
no callback is registered, None will be returned. Finally, to
invoke the callback explicitly just as if the custom markup had been
encountered, call empy.invokeCallback. For instance, @<This text> would be equivalent to the call @empy.invokeCallback("This text").
Invoking a callback (either explicitly with empy.invokeCallback or
by processing a @<...> custom markup) when no callback has been
registered is an error.
Example 61: Custom markup
Source: ⌨️
@{
def callback(contents):
return contents.upper()
empy.registerCallback(callback)
}@
This will be in uppercase: @<This is a test>.
This will also contain angle brackets: @<<This is <also a> test>>.
Output: 🖥️
This will be in uppercase: THIS IS A TEST.
This will also contain angle brackets: THIS IS <ALSO A> TEST.
Deprecated since version 4.1: Custom markup was introduced in EmPy version 3.3 and transformed into extension markup in EmPy version 4.1.
Finalizers#
Every interpreter must shutdown (by the shutdown method being called
either implicitly or explicitly). As part of this process, the
interpreter runs any finalizers that may have been registered with
the interpreter.
Finalizers are callable objects which take zero arguments. The interpreter contains a list of finalizers which are called sequentially in order. If a finalizer raises an exception, any remaining finalizers will not be called that exception will be propagated up.
To add a finalizer, call either the appendFinalizer or
preprendFinalizer interpreter methods. To clear all finalizers,
call the clearFinalizers method.
Note
atExit is an alias for appendFinalizer for backward compatibility
and is now deprecated.
Example 62: Finalizers
Source: ⌨️
@# These are printed in reverse order.
@empy.appendFinalizer(lambda: empy.write("This is the last line.\n"))@
@empy.appendFinalizer(lambda empy=empy: empy.write("This is the penultimate line.\n"))@
@{
import em
class Finalizer:
def __init__(self, interp):
self.interp = interp
def __call__(self):
self.interp.write("This is the third to last line.\n")
finalizer = Finalizer(empy)
empy.appendFinalizer(finalizer)
}@
This is the first line.
Output: 🖥️
This is the first line.
This is the third to last line.
This is the penultimate line.
This is the last line.
Tip
The finalizers are callables which take no arguments when they are called, so if they need a reference to the interpreter to do their work (as the example above), they need to arrange it with a closure, an implicit argument, or by implementing it as an instance which contains a reference to the interpreter. All three of these approaches are illustrated in the example above.
Warning
When using the expand method or standalone function, the StringIO
object which is used to capture the output of the ephemeral
interpreter is processed before finalizers are handled. Thus
attempting to use finalizers to generate output will not work as
expected. Instead, create a dedicated interpreter (Python code):
import em
source = ... # the EmPy source to expand
with em.StringIO() as file:
with em.Interpreter(output=file, ...) as interp:
interp.string(source)
output = file.getvalue()
New in version 2.1: Finalizers were introduced in EmPy version 2.1.
Handlers#
Error handlers are also implemented as plugins. See Error handlers.
Diversions#
EmPy supports an extended form of diversions, which are a mechanism for deferring and playing back output on demand, similar to the functionality included in m4. Multiple “streams” of output can be diverted (deferred) and played back (undiverted) in this manner. A diversion is identified with a name, which is any immutable object such an integer or string. Diversions can be played back multiple times (“replayed”) if desired. When recalled, diverted code is not resent through the EmPy interpreter (although a filter could be set up to do this).
By default, no diversions take place. When no diversion is in effect,
processing output goes directly to the specified output file. This
state can be explicitly requested at any time by calling the
empy.stopDiverting function. It is always legal to call this
function, even when there is currently no active diversion.
When diverted, however, output goes to a deferred location which can
then be recalled later. Output is diverted with the
empy.startDiversion function, which takes an argument that is the
name of the diversion. If there is no diversion by that name, a new
diversion is created and output will be sent to that diversion; if the
diversion already exists, output will be appended to that preexisting
diversion.
Output send to diversions can be recalled in two ways. The first is
through the empy.playDiversion function, which takes the name of the
diversion as an argument. This plays back the named diversion, sends
it to the output, and then erases that diversion. A variant of this
behavior is the empy.replayDiversion, which plays back the named
diversion but does not eliminate it afterwards; empy.replayDiversion
can be repeatedly called with the same diversion name, and will replay
that diversion repeatedly. empy.createDiversion will create a
diversion without actually diverting to it, for cases where you want
to make sure a diversion exists but do not yet want to send anything
to it.
The diversion object itself can be retrieved with
empy.retrieveDiversion. Diversions act as writable file-objects,
supporting the usual write, writelines, flush, and close
methods. The data that has been diverted to them can be manually
retrieved in one of two ways; either through the asString method,
which returns the entire contents of the diversion as a single string,
or through the asFile method, which returns the contents of the
diversion as a readable (not writable) file-like object.
Diversions can also be explicitly deleted without playing them back
with the empy.dropDiversion function, which takes the desired
diversion name as an argument.
Additionally there are three functions which will apply the above
operations to all existing diversions: empy.playAllDiversions,
empy.replayAllDiversions, and empy.dropAllDiversions. The
diversions are handled in lexicographical order by their name. Also,
all three will do the equivalent of a empy.stopDiverting call before
they do their thing.
The name of the current diversion can be requested with the
empy.getCurrentDiversionName function; also, the names of all
existing diversions (in sorted order) can be retrieved with
empy.getAllDiversionNames. empy.isExistingDiversionName will
return whether or not a diversion with the given name exists.
When all processing is finished, the equivalent of a call to
empy.playAllDiversions is done. This can be disabled with the
--no-auto-play-diversions (configuration variable: autoPlayDiversions = False) option.
Example 3: Diversions sample
Source: ⌨️
This text is output normally.
@empy.startDiversion('A')@
(This text was diverted!)
@empy.stopDiverting()@
This text is back to being output normally.
Now playing the diversion:
@empy.playDiversion('A')@
And now back to normal output.
Output: 🖥️
This text is output normally.
This text is back to being output normally.
Now playing the diversion:
(This text was diverted!)
And now back to normal output.
New in version 1.0: Diversions were introduced in EmPy version 1.0.
Filters#
EmPy also supports dynamic filters. Filters are put in place immediately before the final output file, and so are only invoked after all other processing has taken place (including interpreting and diverting). Filters take input, remap it, and then send it to the output. They can be chained together where a series of filters point to each other in series and then finally to the output file.
The current top-level filter can be retrieved with empy.getFilter
(or empy.getFirstFilter). The last filter in the chain (the one
just before the underlying file) can be retrieved with
empy.getLastFilter. The filter can be set with empy.setFilter
(which allows multiple arguments to constitute a chain). To append a
filter at the end of the chain (inserting it just before the
underlying output file), use empy.appendFilter. To prepend it to
the top of the chain, use empy.prependFilter. A filter chain can be
set directly with empy.setFilterChain. And a filter chain can be
reset with empy.resetFilter, removing all filters.
Filters are, at their core, simply file-like objects (minimally
supporting write, flush, and close methods that behave in the
usual way) which, after performing whatever processing they need to
do, send their work to the next file-like object or filter in line,
called that filter’s “sink.” That is to say, filters can be “chained”
together; the action of each filter takes place in sequence, with the
output of one filter being the input of the next. The final sink of
the filter chain will be the output file. Additionally, filters
support a _flush method (note the leading underscore) which will
always flush the filter’s underlying sink; this method should be not
overridden.
Filters also support two additional methods, not part of the
traditional file interface: attach, which takes as an argument a
file-like object (perhaps another filter) and sets that as the
filter’s “sink” — that is, the next filter/file-like object in line.
detach (which takes no arguments) is another method which flushes
the filter and removes its sink, leaving it isolated. Finally,
next, if present, is an attribute which references the filter’s sink
— or None, if the filter does not yet have a sink attached.
To create your own filter, you can create an object which supports the
above described interface, or simply derive from the Filter class
(or one of its subclasses) in the emlib module and override the
relevant methods.
Example 4: Filters sample
Source: ⌨️
@{
# For access to the filter classes.
import emlib
}@
This text is normal.
@empy.appendFilter(emlib.FunctionFilter(lambda x: x.upper()))@
This text is in all uppercase!
@empy.appendFilter(emlib.FunctionFilter(lambda x: '[' + x + ']'))@
Now it's also surrounded by brackets!
(Note the brackets are around output as it is sent,
not at the beginning and end of each line.)
@empy.resetFilter()@
Now it's back to normal.
Output: 🖥️
This text is normal.
THIS TEXT IS IN ALL UPPERCASE!
[NOW IT'S ALSO SURROUNDED BY BRACKETS!
(NOTE THE BRACKETS ARE AROUND OUTPUT AS IT IS SENT,
NOT AT THE BEGINNING AND END OF EACH LINE.)
]Now it's back to normal.
New in version 1.3: Filters were introduced in EmPy version 1.3.
Modules#
EmPy also supports importing EmPy files as modules, the same way that
Python can import Python modules. EmPy modules are files with an .em
extension (configurable with --module-extension (configuration variable: moduleExtension))
located somewhere in the path. EmPy modules are imported with the
import statement just as Python modules are imported. EmPy modules
are implemented via the importlib
architecture.
EmPy modules are activated by installing a meta path finder instance
in sys.meta_path. By default, it is installed before all the other
meta path finders; this can be modified with
--module-finder-index (configuration variable: moduleFinderIndex) — it represents the index
to insert the module finder in the meta path, with 0 being at the
beginning; a negative value indicates that it should be appended.
This module path finder is installed when the first interpreter is
created. It is designed so that if an import statement is executed
outside of a running interpreter, the EmPy module path finder will be
skipped. When all interpreters are shut down, the meta path finder is
not removed from the sys.meta_path; it will become inactive since
there is no proxy installed and no interpreter is running.
EmPy modules are real modules and have the same attributes and
behavior as Python modules. When an EmPy module is imported, the
module is created, and then the pseudodmodule is placed in that
module’s globals (or its attributes are if -f/--flatten (environment variable: EMPY_FLATTEN, configuration variable: doFlatten = True) is
set). After the module is so prepared, the source file is expanded in
a new interpreter context with the globals pointing to that new
module’s contents.
Module support can disabled with -g/--disable-modules (configuration variable: supportModules = False).
An EmPy document can determine whether it is being imported as a
module or expanded naturally by checking for the globals __name__,
__file__, and/or __spec__.
As an example, given this file names.em somewhere in your path:
@[def upper(x)]@x.upper()@[end def]@
@[def capitalize(x)]@x.capitalize()@[end def]@
@[def lower(x)]@x.lower()@[end def]@
Then (with test.em found in /tmp):
Example 63: Modules
Source: ⌨️
@{
import names
}@
Module: @names
Uppercase: @names.upper("uppercase").
Lowercase: @names.lower("LOWERCASE").
Capitalize: @names.capitalize("capitalize").
Output: 🖥️
Module: <module 'names' from '/tmp/names.em'>
Uppercase: UPPERCASE.
Lowercase: lowercase.
Capitalize: Capitalize.
Important
To change the filename extension used to detect EmPy modules (which
defaults to .em), use
--module-extension (configuration variable: moduleExtension).
The meta path finder used to support modules is installed when the
first interpreter is created; therefore, changing the configuration
variable moduleExtension after the interpreter is up
and running will have no effect. To use configurations to change the
module extension, use the -c/--config-file=FILENAME (environment variable: EMPY_CONFIG) or
--config=STATEMENTS command line options, or create a
Configuration object manually and then pass it into the first
Interpreter instance created. For instance, to use the extension
.empy:
% em.py --module-extension=.empy ... ...
or
% em.py --config='moduleExtension = ".empy"' ... ...
or (Python code):
import em
config = em.Configuration(modulExtension='.empy')
interp = em.Interpreter(config=config, ...)
... use interp here ...
Tip
By default, any output generated by an EmPy module will be sent to the output. Often this is undesirable, as modules are usually intended to define classes, functions and variables, rather than generate output. Using natural spacing between these definitions — particularly if they are long and take up many lines themselves — would normally result in blank lines in the output. For instance, when importing this module:
@[def f(...)]@
... definition of f here ...
@[end def]@
@[def g(...)]@
... definition of g here ...
@[end def]@
a blank line will be rendered since there is one between the two function definitions. That is unfortunate since the blank line helps to separate the two definitions. This can be addressed in a few different ways:
Wrap the EmPy module in switch markup (
@- ... NL,@+ ... NL). Something like this:@- @[def f(...)]@ ... definition of f here ... @[end def]@ @[def g(...)]@ ... definition of g here ... @[end def]@ @+
Systematically use whitespace markup
@ NLor comment markup@#to make sure no blank lines are generated:@[def f(...)]@ ... definition of f here ... @[end def]@ @ @[def g(...)]@ ... definition of g here ... @[end def]@
Disable module output with
-j/--disable-import-output(configuration variable:enableImportOutput = False).
Warning
EmPy modules rely on the importlib architecture in order to
function, so they are only supported in Python version 3.4 and up.
Also, IronPython’s importlib implementation is flawed, so modules do
not function in IronPython.
To see if modules are not supported in your interpreter, verify that
the string !modules is an element of the compat
pseudomodule/interpreter attribute.
New in version 4.2: Modules were introduced in EmPy version 4.2.
Hooks#
The EmPy system allows for the registration of hooks with a running EmPy interpreter. Hooks are objects, registered with an interpreter, whose methods represent specific hook events. Any number of hook objects can be registered with an interpreter, and when a hook is invoked, the associated method on each one of those hook objects will be called by the interpreter in sequence. The method name indicates the type of hook, and it is called with a keyword list of arguments corresponding the event arguments.
To use a hook, derive a class from emlib.Hook and override the
desired methods (with the same signatures as they appear in the base
class). Create an instance of that subclass, and then register it
with a running interpreter with the empy.addHook function. A hook
instance can be removed with the empy.removeHook function.
More than one hook instance can be registered with an interpreter; in
such a case, the appropriate methods are invoked on each instance in
the order in which they were appended. To adjust this behavior, an
optional prepend argument to the empy.addHook function can be used
dictate that the new hook should placed at the beginning of the
sequence of hooks, rather than at the end (which is the default).
Also there are explicit empy.appendHook and empy.prependHook
functions.
All hooks can be enabled and disabled entirely for a given
interpreter; this is done with the empy.enableHooks and
empy.disableHooks functions. By default hooks are enabled, but
obviously if no hooks have been registered no hooks will be called.
Whether hooks are enabled or disabled can be determined by calling
empy.areHooksEnabled. To get the list of registered hooks, call
empy.getHooks. All the hooks can be removed with empy.clearHooks.
Finally, to invoke a hook manually, use empy.invokeHook.
For a list of supported hooks, see Hook methods or the Hook
class definition in the emlib module. (There is also an
AbstractHook class in this module which does not have blank stubs
for existing hook methods in case a user wishes to create them
dynamically.)
For example:
Example 5: Hooks sample
Source: ⌨️
@# Modify the backquote markup to prepend and append backquotes
@# (say, for a document rendering system, cough cough).
@{
import emlib
class BackquoteHook(emlib.Hook):
def __init__(self, interp):
self.interp = interp
def preBackquote(self, literal):
self.interp.write('`' + literal + '`')
return True # return true to skip the standard behavior
empy.addHook(BackquoteHook(empy))
}@
Now backquote markup will render with backquotes: @
@`this is now in backquotes`!
Output: 🖥️
Now backquote markup will render with backquotes: `this is now in backquotes`!
Changed in version 4.0: Hooks were originally introduced in EmPy version 2.0, much improved in version 3.2, and revamped again in version 4.0.
Hook methods#
Hook at... methods#
These hooks are called when a self-contained event occurs.
atInstallProxy(proxy, new)A
sys.stdoutproxy was installed. The Boolean valuenewindicates whether or not the proxy was preexisting.atUninstallProxy(proxy, done)A
sys.stdoutproxy was uninstalled. The Boolean valuedoneindicates whether the reference count went to zero (and so the proxy has been completely removed).atStartup()The interpreter has started up.
atReady()The interpreter has declared itself ready for processing.
atFinalize()The interpreter is finalizing.
atShutdown()The interpreter is shutting down.
atParse(scanner, locals)The interpreter is initiating a parse action with the given scanner and locals dictionary (which may be
None).atToken(token)The interpreter is expanding a token.
atHandle(info, fatal, contexts)The interpreter has encountered an error. The
infoparameter is a 3-tuple error (error type, error, traceback) returned fromsys.exc_info,fatalis a Boolean indicating whether the interpreter should exit afterwards, andcontextsis the context stack.atInteract()The interpreter is going interactive.
Hook context methods#
pushContext(context)This context is being pushed.
popContext(context)This context has been popped.
setContext(context)This context has been set or modified.
restoreContext(context)This context has been restored.
Hook pre.../post... methods#
The pre... hooks are invoked before a token expands. The hook can
return a true value to indicate that it has intercepted the expansion
and the token should cancel native expansion. Not explicitly
returning anything, as in standard Python, is equivalent to returning
None, which is a false value, which continues expansion:
Example 64: Hook pre... methods
Source: ⌨️
@{
import emlib
class Hook(emlib.Hook):
def __init__(self, interp):
self.interp = interp
def preString(self, string):
self.interp.write('[' + string + ']')
return True
empy.addHook(Hook(empy))
}@
@# Now test it:
@"Hello, world!"
Output: 🖥️
["Hello, world!"]
Tip
It’s typical to want to have an instance of the interpreter/pseudomodule available to the hook, but it is neither done automatically nor is it required.
The post... hooks are invoked after a non-intercepted token finishes
expanding. Not all pre... hooks have a corresponding post...
hook. The post... hooks take at most one argument (the result of
the token expansion, if applicable) and their return value is ignored.
preLineComment(comment),postLineComment()The line comment
@#... NLwith the given text.preInlineComment(comment),postInlineComment()The inline comment
@*...*with the given text.preWhitespace(whitespace)The whitespace token
@ WSwith the given whitespace.prePrefix()The prefix token
@@.preString(string),postString()The string token
@'...', etc. with the given string.preBackquote(literal),postBackquote(result)The backquote token
@`...`with the given literal.preSignificator(key, value, stringized),postSignificator()The significator token
@%... NL, etc. with the given key, value and a Boolean indicating whether the significator is stringized.preContextName(name),postContentName()The context name token
@?...with the given name.preContextLine(line),postContextLine()The context line token
@!...with the given line.preExpression(pairs, except, locals),postExpression(result)The expression token
@(...)with the given if-then run pairs, the except run, and the locals dictionary (which may beNone).preSimple(code, subtokens, locals),postSimple(result)The simple expression token
@word(etc.) with the given code, subtokens and locals.preInPlace(code, locals),postInPlace(result)The in-place expression token
@$...$...$with the given code (first section) and locals (which may beNone).preStatement(code, locals),postStatement()The statement token
@{...}with the given code and locals (which may beNone).preControl(type, rest, locals),postControl()The control token
@[...]of the given type, with the rest run and locals (which may be None).preEscape(code),postEscape()The control token
@\...with the resulting code.preDiacritic(code),postDiacritic()The diacritic token
@^...with the resulting code.preIcon(code),postIcon()The icon token
@|...with the resulting code.preEmoji(name),postEmoji()The emoji token
@:...:with the given name.preExtension(name, contents, depth),postExtension(result)An extension with the given name, contents and depth was invoked.
preCustom(contents),postCustom()The custom token
@<...>with the given contents.
Hook before.../after... methods#
The before... and after... hooks are invoked before and after (go
figure) mid-level expansion activities are performed. Any locals
argument indicates the locals dictionary, which may be None.
If the expansion returns something relevant, it is passed as a
result argument to the corresponding after... method.
beforeProcess(command, n),afterProcess()The given command (with index number) is being processed.
beforeInclude(file, locals, name),afterInclude()The given file is being processed with the given name.
beforeExpand(string, locals, name),afterExpand(result)empy.expandis being called with the given string and name.beforeTokens(tokens, locals),afterTokens(result)The given list of tokens is being processed.
beforeFileLines(file, locals),afterFileLines()The given file is being read by lines.
beforeFileChunks(file, locals),afterFileChunks()The given file is being read by buffered chunks.
beforeFileFull(file, locals),afterFileFull()The given file is being read fully.
beforeString(string, locals),afterString()The given string is being processed.
beforeQuote(string),afterQuote(result)The given string is being quoted.
beforeEscape(string),afterEscape(result)The given string is being escaped.
beforeSignificate(key, value, locals),afterSignificate()The given key/value pair is being processed.
beforeCallback(contents),afterCallback()The custom callback is being processed with the given contents.
beforeAtomic(name, value, locals),afterAtomic()The given atomic variable setting with the name and value is being processed.
beforeMulti(names, values, locals),afterMulti()The given complex variable setting with the names and values is being processed.
beforeImport(name, locals),afterImport()A module with the given name is being imported.
beforeFunctional(code, lists, locals),afterFunctional(result)A functional markup is with the given code and argument lists (of EmPy code) is being processed.
beforeEvaluate(expression, locals, write),afterEvaluate(result)An evaluation markup is being processed with the given code and a Boolean indicating whether or not the results are being written directly to the output stream or returned.
beforeExecute(statements, locals),afterExecute()A statement markup is being processed.
beforeSingle(source, locals),afterSingle(result)A “single” source (either an expression or a statement) is being compiled and processed.
beforeFinalizer(final),afterFinalizer()The given finalizer is being processed. If the
beforeFinalizerhook returns true for a particular finalizer, then that finalizer will not be called.
See also
The list of hook methods is available in the hooks help topic and is
summarized here.
Customization#
The behavior of an EmPy system can be customized in various ways.
Command line options#
EmPy uses a standard GNU-style command line options processor with
both short and long options (e.g., -p or --prefix). Short
options can be combined into one word, and options can have values
either in the next word or in the same word separated by an =. An
option consisting of only -- indicates that no further option
processing should be performed.
EmPy supports the following options:
-V/--versionPrint version information exit. Repeat the option for more details (see below).
-W/--infoPrint additional information, including the operating system, Python implementation and Python version number.
-Z/--detailsPrint all additional details about the running environment, including interpreter, system, platform, and operating system release details.
-h/--helpPrint basic help and exit. Repeat the option for more extensive help. Specifying
-honce is equivalent to-H default; twice to-H more, and three or more times to-H all(see below).-H/--topics=TOPICSPrint extended help by topic(s). Topics are a comma-separated list of the following choices:
Topic
Description
usageBasic command line usage
optionsCommand line options
simpleSimple (one-letter) command line options (why not)
markupMarkup syntax
escapesEscape sequences
environEnvironment variables
pseudoPseudomodule attributes and functions
variablesConfiguration variable attributes
methodsConfiguration methods
hookHook methods
namedNamed escapes (control codes)
diacriticsDiacritic combiners
iconsIcons
emojisUser-specified emojis (optional)
hintsUsage hints
topicsThis list of topics
defaultusage,options,markup,hintsandtopicsmoreusage,options,markup,escapes,environ,hintsandtopicsallusage,options,markup,escapes,environ,pseudo,config,controls,diacritics,icons,hintsAs a special case,
-Hwith no topic argument is treated as-H allrather than error.-v/--verboseThe EmPy system will print debugging information to
sys.stderras it is doing its processing.
-p/--prefix=CHAR(environment variable:EMPY_PREFIX, configuration variable:prefix)Specify the desired EmPy prefix. It must consist of a single Unicode code point (or character). To specify no prefix (see below), provide an empty string, the string
Noneornone, or set theprefixconfiguration variable toNone. Defaults to@.--no-prefixSpecify that EmPy use no prefix. In this mode, will only process text and perform no markup expansion. This is equivalent to specifying
-p '', or setting theprefixconfiguration variable toNone.-q/--no-outputUse a null file for the output file. This will result in no output at all.
-m/--pseudomodule=NAME(environment variable:EMPY_PSEUDO, configuration variable:pseudomoduleName)Specify the name of the EmPy pseudomodule/interpreter. Defaults to
empy.-f/--flatten(environment variable:EMPY_FLATTEN, configuration variable:doFlatten = True)Before processing, move the contents of the
empypseudomodule into the globals, just as ifempy.flattenGlobals()were executed immediately after starting the interpreter. This is the equivalent of executingfrom empy import *(though since the pseudomodule is not a real module that statement is invalid). e.g.,empy.includecan be referred to simply asincludewhen this flag is specified on the command line.-k/--keep-going(configuration variable:exitOnError = False)Don’t exit immediately when an error occurs. Execute the error handler but continue processing EmPy tokens.
-e/--ignore-errors(configuration variable:ignoreErrors = True)Ignore errors completely. No error dispatcher or handler is executed and token processing continues indefinitely. Implies
-k/--keep-going.-r/--raw-errors(environment variable:EMPY_RAW_ERRORS, configuration variable:rawErrors = True)After logging an EmPy error, show the full Python traceback that caused it. Useful for debugging.
-s/--brief-errors(configuration variable:verboseErrors = False)When printing an EmPy error, show only its arguments and not its keyword arguments. This is in contrast to the default (verbose) where keyword arguments are shown.
--verbose-errors(configuration variable:verboseErrors = True)When printing an EmPy error, show both its arguments and its (sorted) keyword arguments. This is the default.
-i/--interactive(environment variable:EMPY_INTERACTIVE, configuration variable:goInteractive = True)Enter interactive mode after processing is complete by continuing to process EmPy markup from the input file, which is by default
sys.stdin); this can be changed with theinputinterpreter attribute. This is helpful for inspecting the state of the interpreter after processing.-d/--delete-on-error(environment variable:EMPY_DELETE_ON_ERROR, configuration variable:deleteOnError)If an error occurs, delete the output file; requires the use of the one of the output options such as
-o/--output=FILENAME. This is useful when running EmPy under a build systemn such as GNU Make. If this option is not selected and an error occurs, the output file will stop when the error is encountered.-n/--no-proxy(environment variable:EMPY_NO_PROXY, configuration variable:useProxy)Do not install a proxy in
sys.stdout. This will make EmPy thread safe but writing tosys.stdoutwill not be captured or processed in any way.--config=STATEMENTSPerform the given configuration variable assignments. This option can be specified multiple times.
-c/--config-file=FILENAME(environment variable:EMPY_CONFIG)Read and process the given configuration file(s), separated by the platform-specific path delimiter (
;on Windows,:on other operating systems). This option can be specified multiple times.--config-variable=NAME(configuration variable:configVariableName)Specify the variable name corresponding to the current configuration when configuration files are processed. Defaults to
_.-C/--ignore-missing-config(configuration variable:missingConfigIsError = False)Ignore missing files while reading and processing configurations. By default, a missing file is an error.
-o/--output=FILENAMESpecify the file to write output to. If this argument is not used, final output is written to the underlying
sys.stdout.-a/--append=FILENAMESpecify the file to append output to. If this argument is not used, final output is appended to the underlying
sys.stdout.-O/--output-binary=FILENAMESpecify the file to write output to and open it as binary.
-A/--append-binary=FILENAMESpecify the file to append output to and open it as binary.
--output-mode=MODESpecify the output mode to use.
--input-mode=MODESpecify the input mode to use. Defaults to
'r'.-b/--buffering(environment variable:EMPY_BUFFERING, configuration variable:buffering)Specify the buffering to use. Use an integer to specify the maximum number of bytes to read per block or one of the following string values:
Name
Value
Description
full-1
Use full buffering
none0
Use no buffering
line1
Use line buffering
default16384
Default buffering
If the choice of buffering is incompatible with other settings, a
ConfigurationErroris raised. This option has no effect on interactive mode, assys.stdinis already open. Defaults to 16384.--default-bufferingUse default buffering.
-N/--no-bufferingUse no buffering.
-L/--line-bufferingUse line buffering.
-B/--full-bufferingUse full buffering.
-I/--import=MODULESImport the given Python (not EmPy) module(s) into the interpreter globals before main document processing begins. To specify more than one module to import, separate the module names with commas or use multiple
-I/--import=MODULESoptions.Variations on the Python
importstatement can be expressed with the following arguments shortcuts:Argument shortcut patterns
Python equivalent
Ximport XX as Yimport X as YX=Yimport X as YX:Yfrom X import YX:Y as Zfrom X import Y as ZX:Y=Zfrom X import Y as ZX,Yimport X, YFor convenience, any
+character in the argument is replaced with a space.-D/--define=DEFNDefine the given variable into the interpreter globals before main document processing begins. This is executed as a Python assignment statement (
variable = ...); if it does not contain a=character, then the variable is defined in the globals with the valueNone.-S/--string=STRDefine the given string variable into the interpreter globals before main document processing begins. The value is always treated as a string and never evaluated; if it does not contain a
=character, then the variable is defined as the empty string ('').-P/--preprocess=FILENAMEProcess the given EmPy (not Python) file before main document processing begins.
-Q/--postprocess=FILENAMEProcess the given EmPy (not Python) file after main document processing begins.
-E/--execute=STATEMENTExecute the given arbitrary Python (not EmPy) statement before main document processing begins.
-K/--postexecute=STATEMENTExecute the given arbitrary Python (not EmPy) statement after main document processing begins.
-F/--file=FILENAMEExecute the given Python (not EmPy) file before main document processing begins.
-G/--postfile=FILENAMEExecute the given Python (not EmPy) file after main document processing begins.
-X/--expand=MARKUPExpand the given arbitrary EmPy (not Python) markup before main document processing begins.
-Y/--postexpand=MARKUPExpand the given arbitrary EmPy (not Python) markup after main document processing begins.
--preinitializer=FILENAMEExecute the given Python file locally just before creating the main interpreter. Used for tests.
--postinitializer=FILENAMEExecute the given Python file locally just after shutting edown the main interpreter. Used for tests.
-w/--pause-at-end(configuration variable:pauseAtEnd)Prompt for a line of input after all processing is complete. Useful for systems where the window running EmPy would automatically disappear after EmPy exits (e.g., Windows). By default, the input file used is
sys.stdin, so this will not work when redirecting stdin to an EmPy process. This can be changed with theinputinterpreter attribute.-l/--relative-path(configuration variable:relativePath)Prepend the location of the EmPy script to Python’s
sys.path. This is useful when the EmPy scripts themselves import Python .py modules in that same directory.--replace-newlines(configuration variable:replaceNewlines = True)Replace newlines in (Python) expressions before evaluation.
--no-replace-newlines(configuration variable:replaceNewlines = False)Don’t replace newlines in (Python) expressions before evaluations. This is the default.
--ignore-bangpaths(configuration variable:ignoreBangpaths = True)Treat bangpaths as comments. By default, bangpaths (starting lines that begin with the characters
#!) are treated as comments and ignored.--no-ignore-bangpaths(configuration variable:ignoreBangpaths = False)Do not treat bangpaths as comments. This is the opposite of the default.
--none-symbol(configuration variable:noneSymbol)The string to write when expanding the value
None. Defaults toNone, which will result in no output.--no-none-symbolDo not write any preset string when expanding
None; equivalent to settingnoneSymboltoNone.--expand-user(configuration variable:expandUserConstructions = True)Expand user constructions (
~user) in configuration file pathnames. This is the default.--no-expand-user(configuration variable:expandUserConstructions = False)Do not expand user constructions (
~user) in configuration file pathnames. By default they are expanded.--auto-validate-icons(configuration variable:autoValidateIcons = True)Auto-validate icons when an icon markup is first used. This is the default. See below.
--no-auto-validate-icons(configuration variable:autoValidateIcons = False)Do not auto-validate icons when an icon markup is first used. See below.
--starting-line(configuration variable:startingLine)Specify an integer representing the default starting line for contexts. Default is 1.
--starting-column(configuration variable:startingColumn)Specify an integer representing the default starting column for contexts. Default is 1.
--emoji-modules(configuration variable:emojiModuleNames)A comma-separated list of emoji modules to try to use for the emoji markup (
@:...:). See below. Defaults toemoji,emojis,emoji_data_python,unicodedata.--no-emoji-modulesOnly use
unicodedataas an emoji module; disable all the third-party emoji modules.--disable-emoji-modulesDisable all emoji module usage; just rely on the
emojisattribute of the configuration. See below.--ignore-emoji-not-found(configuration variable:emojiNotFoundIsError = False)When using emoji markup (
@:...:), do not raise an error when an emoji is not found; just pass the:...:text through.-u/--binary/--unicode(environment variable:EMPY_BINARY, configuration variable:useBinary)Operate in binary mode; open files in binary mode and use the
codecsmodule for Unicode support. This is necessary in older versions of Python 2.x.-x/--encoding=ESpecify both input and output Unicode encodings. Requires specifying both an input and an output file.
--input-encoding=E(environment variable:EMPY_INPUT_ENCODING, configuration variable:inputEncoding)Specify the input Unicode encoding. Requires specifying an input file rather than
sys.stdout.Note
Specifying a non-default encoding when using interactive mode (
sys.stdin) raises aConfigurationError.--output-encoding=E(environment variable:EMPY_OUTPUT_ENCODING, configuration variable:outputEncoding)Specify the output Unicode encoding. Requires specifying an output file rather than
sys.stdout.Note
Specifying a non-default encoding when using
sys.stdoutraises aConfigurationError.-y/--errors=ESpecify both input and output Unicode error handlers.
--input-errors=E(environment variable:EMPY_INPUT_ERRORS, configuration variable:inputErrors)Specify the input Unicode error handler.
Note
Specifying a non-default error handler when using interactive mode (
sys.stdin) raises aConfigurationError.--output-errors=E(environment variable:EMPY_OUTPUT_ERRORS, configuration variable:outputErrors)Specify the output Unicode error handler.
Note
Specifying a non-default error handler when using
sys.stdoutraises aConfigurationError.-z/--normalization-form=F(configuration variable:normalizationForm)Specify the Unicode normalization to perform when using the diacritics markup (
@^...). Specify an empty string ('') to skip normalization. Defaults toNFKCfor modern versions of Python and''for very old versions of Python 2.x.--auto-play-diversions(configuration variable:autoPlayDiversions = True)Before exiting, automatically play back any remaining diversions. This is the default.
--no-auto-play-diversions(configuration variable:autoPlayDiversions = False)Before exiting, do not automatically play back any remaining diversions. By default such diversions are played back.
--check-variables(configuration variable:checkVariables = True)When modifying configuration variables, by default the existence and proper type of these variables is checked; anomalies will raise a
ConfigurationError. This is the default.--no-check-variables(configuration variable:checkVariables = False)When modifying configuration variables, normally the existence and types of these variables is checked and if it doesn’t exist or it is attempting to be assigned to an incompatible type, it will raise a
ConfigurationError. To override this behavior, use this flag.--path-separator(configuration variable:pathSeparator)The path separator delimiter for specifying configuration paths. Defaults to
;on Windows and:on all other platforms.--enable-modules(configuration variable:supportModules = True)Enable EmPy module support (Python 3.4 and up). The default.
-g/--disable-modules(configuration variable:supportModules = False)Disable EmPy module support.
--module-extension(configuration variable:moduleExtension)The filename extension for EmPy modules. Defaults to
.em.--module-finder-index(configuration variable:moduleFinderIndex)When installing the module finder, which allows EmPy module support, use this index as the position in the meta path to insert it. Zero means that it will be inserted into the front of the list, one means the second, etc. Negative values means that it will appended. Defaults to zero.
--enable-import-output(configuration variable:enableImportOutput = True)Output from imported EmPy modules is allowed through. The default.
-j/--disable-import-output(configuration variable:enableImportOutput = False)Output from imported EmPy modules is suppressed.
--context-format(configuration variable:contextFormat)Specify the format for printing contexts. See below.
--success-code=N(configuration variable:successCode)Specify the exit code for the Python interpreter on success. Defaults to 0.
--failure-code=N(configuration variable:failureCode)Specify the exit code for the Python interpreter when a processing error occurs. Defaults to 1.
--unknown-code=N(configuration variable:unknownCode)Specify the exit code for the Python interpreter when an invalid configuration (such as unknown command line options) is encountered. Defaults to 2.
See also
The list of command line options is available in the options help
topic and is summarized here.
Environment variables#
The following environment variables are supported:
EMPY_OPTIONSSpecify additional command line options to be used. These are in effect added to the start of the command line and parsed before any explicit command line options and processing begins.
For example, this will run the EmPy interpreter as if the
-rand-dcommand line options were specified:
% export EMPY_OPTIONS='-r -d'; em.py ...
EMPY_CONFIG(command line option:-c/--config-file=FILENAME)Specify the configuration file(s) to process before main document processing begins.
EMPY_PREFIX(command line option:-p/--prefix=CHAR, configuration variable:prefix)Specify the prefix to use when processing.
EMPY_PSEUDO(command line option:-m/--pseudomodule=NAME, configuration variable:pseudomoduleName)Specify the name of the pseudomodule/interpreter to use when processing.
EMPY_FLATTEN(command line option:-f/--flatten, configuration variable:doFlatten = True)If defined, flatten the globals before processing.
EMPY_RAW_ERRORS(command line option:-r/--raw-errors, configuration variable:rawErrors = True)If defined, after an error occurs, show the full Python tracebacks of the exception.
EMPY_INTERACTIVE(command line option:-i/--interactive, configuration variable:goInteractive = True)If defined, enter interactive mode by processing markup from
sys.stdinafter main document processing is complete.EMPY_DELETE_ON_ERROR(command line option:-d/--delete-on-error, configuration variable:deleteOnError)If defined, when an error occurs, delete the corresponding output file.
EMPY_NO_PROXY(command line option:-n/--no-proxy, configuration variable:useProxy)If defined, do not install a
sys.stdoutproxy.EMPY_BUFFERING(command line option:-b/--buffering, configuration variable:buffering)Specify the desired file buffering.
EMPY_BINARY(command line option:-u/--binary/--unicode, configuration variable:useBinary)If defined, use binary mode.
EMPY_ENCODINGSpecify the desired input and output Unicode encodings.
EMPY_INPUT_ENCODING(command line option:--input-encoding=E, configuration variable:inputEncoding)Specify the desired input Unicode encoding only.
EMPY_OUTPUT_ENCODING(command line option:--output-encoding=E, configuration variable:outputEncoding)Specify the desired output Unicode encoding only.
EMPY_ERRORSSpecify the desired input and output Unicode error handler.
EMPY_INPUT_ERRORS(command line option:--input-errors=E, configuration variable:inputErrors)Specify the desired input Unicode error handler.
EMPY_OUTPUT_ERRORS(command line option:--output-errors=E, configuration variable:outputErrors)Specify the desired output Unicode error handler.
See also
The list of environment variables is available in the environ help
topic and is summarized here.
New in version 2.2: Environment variables were first introduced in EmPy version 2.2, and revamped in version 4.0.
Configuration#
Configurations are objects which determine the behavior of an EmPy
interpreter. They can be created with an instance of the
Configuration class and have a set of attributes (configuration
variables) which can be modified. Most configuration variables
correspond to a command line option. The configuration instance also
contains supporting methods which are used by the interpreter which
can be overridden.
When configuration variables are modified, they are by default checked
to make sure have a known name and that they have the correct type; if
not, a ConfigurationError will be raised. This behavior can be
disabled with --no-check-variables (configuration variable: checkVariables = False).
When a configuration is assigned to an interpreter, it exists as a
config attribute of the empy pseudomodule and can be modified by a
running EmPy system. Configurations can be shared between multiple
interpreters if desired.
Example 65: Configuration instances
Source: ⌨️
@{
empy.config.prefix = '$'
}$
${
print("The EmPy prefix is now $, not @!")
}$
Output: 🖥️
The EmPy prefix is now $, not @!
Tip
This example shows a quirk of changing configurations in the middle of
processing an EmPy document; the prefix changes from a @ to a $
by the end of the first statement markup, so a $ and a newline is
required to suppress the trailing newline; a @ would have been sent
to the output unchanged since it is no longer the prefix. Use
command line options, environment
variables or configuration
files to avoid issues like this, as they are
processed before any EmPy document.
For changing the prefix, use -p/--prefix=CHAR (environment variable: EMPY_PREFIX, configuration variable: prefix).
Configuration files#
Configuration files are snippets of Python (not EmPy) code which
can be executed under an EmPy system to modify the current
configuration. By convention they have the extension .conf. though
this is not a requirement. Configuration files are processed before
any expansion begins and are specified with the -c/--config-file=FILENAME (environment variable: EMPY_CONFIG) command line option; a list of configuration files can be
specified with a : delimiter (; on Windows); the delimiter can be
specified with --path-separator (configuration variable: pathSeparator). A nonexistent
configuration file specified in this way is an error unless
-C/--ignore-missing-config (configuration variable: missingConfigIsError = False) is specified.
When a configuration file is processed, its contents are executed in a Python (not EmPy) interpreter and then any resulting variable assignments are assigned to the configuration instance. So:
prefix = '$'
is a simple configuration file which will change the EmPy prefix to
$.
Any resulting variable beginning with an underscore will be ignored. Thus these variables can be used as auxiliary variables in the configuration file. For example, this configuration file will define custom emojis for the numbered keycaps:
emojis = {}
for _x in range(10):
emojis[str(_x)] = '{}\ufe0f\u20e3'.format(_x)
Finally, when a configuration file is processed, the current
configuration instance is presented as a variable named _ (this can
be changed with --config-variable=NAME (configuration variable: configVariableName)). The
following example does the same as the previous example but uses the
dedicated variable:
_.emojis.update(((str(_x), '{}\ufe0f\u20e3'.format(_x)) for _x in range(10)))
Tip
To make a set of configuration files automatic loaded by EmPy, use the
EMPY_CONFIG environment variable in your startup
shell:
% export EMPY_CONFIG=~/path/to/default.conf
To make a more general set of options available, set EMPY_OPTIONS.
Configuration variables#
The following configuration variables (attributes of a Configuration
object) exist with the given types and their corresponding command
line options and environment variables. Default values are shown
after a = sign. When a corresponding command line option exists,
See Command line options for more detailed information.
name: str = 'default'The name of this configuration. It is for organizational purposes and is not used directly by the EmPy system.
notes = NoneArbitrary data about this configuration. It can be anything from an integer to a string to a dictionary to a class instance, or its default,
None. It is for organizational purposes and is not used directly by the EmPy system.prefix: str = '@'(command line option:-p/--prefix=CHAR, environment variable:EMPY_PREFIX)The prefix the interpreter is using to delimit EmPy markup. Must be a single Unicode code point (character).
pseudomoduleName: str = 'empy'(command line option:-m/--pseudomodule=NAME, environment variable:EMPY_PSEUDO)The name of the pseudomodule for this interpreter.
verbose: bool = FalseIf true, print debugging information before processing each EmPy token.
rawErrors: bool = False(command line option:-r/--raw-errors, environment variable:EMPY_RAW_ERRORS)If true, print a Python traceback for every exception that is thrown.
exitOnError: bool = True(command line option:-k/--keep-going)If true, exit the EmPy interpreter after an error occurs. If false, processing will continue despite the error.
ignoreErrors: bool = False(command line option:-e/--ignore-errors)If true, all errors are ignored by the EmPy interpreter. Setting this to true also implies
exitOnErroris false.contextFormat: str = '%(name)s:%(line)d:%(column)d'(command line option:--context-format)The string format to use to render contexts. EmPy will automatically determine whether or not it should use the
%operator or thestr.formatmethod with this format. See Context formatting for more details.goInteractive: bool = False(command line option:-i/--interactive, environment variable:EMPY_INTERACTIVE)When done processing the main EmPy document (if any), go into interactive mode by running a REPL loop with
sys.stdin. If such document is specified (i.e., EmPy is invoked with no arguments), go into interactive mode as well.deleteOnError: bool = False(command line option:-d/--delete-on-error, environment variable:EMPY_DELETE_ON_ERROR)If an output file is chosen (e.g., with
-o/--output=FILENAMEor one of the other such options) and an error occurs, delete the output file. If this is set to true with output set tosys.stdout, a ConfigurationError will be raised.doFlatten: bool = False(command line option:-f/--flatten, environment variable:EMPY_FLATTEN)Flatten the contents of the
empypseudomodule into the globals rather than having them all under the pseudomodule name.useProxy: bool = True(command line option:-n/--no-proxy, environment variable:EMPY_NO_PROXY)If true, install a proxy object for
sys.stdout. This should be true if any output is being done viaprintorsys.stdout.write.relativePath: bool = False(command line option:-l/--relative-path)If true, the directory of the EmPy script’s path will be prepended to Python’s
sys.path.buffering: int = 16384(command line option:-b/--buffering, environment variable:EMPY_BUFFERING)Specify the buffering for the input and output files.
replaceNewlines: bool = False(command line option:--no-replace-newlines)If true, newlines in emoji names, Unicode character name escape markup, and code evaluation will be changed to spaces. This can help when writing EmPy with a word-wrapping editor.
ignoreBangpaths: bool = True(command line option:--no-ignore-bangpaths)If true, a bangpath (the first line of a file which starts with
#!) will be treated as an EmPy comment, allowing the creation of EmPy executable scripts. If false, it will not be treated specially and will be rendered to the output.noneSymbol: str = None(command line option:--none-symbol)When an EmPy expansion evaluates to None (e.g.,
@(None)), this is the string that will be rendered to the output stream. If set toNone(the default), no output will be rendered.missingConfigIsError: bool = True(command line option:-C/--ignore-missing-config)If a configuration file is specified with
-c/--config-file=FILENAMEbut does not exist, if this variable is true an error will be raised.pauseAtEnd: bool = False(command line option:-w/--pause-at-end)When done processing EmPy files, read a line from
sys.stdinbefore exiting the interpreter. This can be useful when testing under consoles on Windows.startingLine: int = 1(command line option:--starting-line)The line to start with in contexts.
startingColumn: int = 1(command line option:--starting-column)The column to start with in contexts.
significatorDelimiters: tuple = ('__', '__')A 2-tuple of strings representing the prefix and suffix to add to significator names in order to determine what name to give them in the globals.
emptySignificator: object = NoneThe default value to use for non-stringized significators.
autoValidateIcons: bool = True(command line option:--no-auto-validate-icons)When icons are used with a custom dictionary, a preprocessing phase needs to be done to make sure that all icon starting substrings are marked in the
iconsdictionary. If this variable is false, this extra processing step will not be done; this is provided if the user wants to specify their own properly-validated icons dictionary and wishes to avoid a redundant step.emojiModuleNames: list[str] = ['emoji', 'emojis', 'emoji_data_python', 'unicodedata'](command line option:--emoji-modules)The list of names of supported emoji modules that the EmPy system will attempt t use at startup.
emojiNotFoundIsError: bool = True(command line option:--ignore-emoji-not-found)If true, a non-existing emoji is an error.
useBinary: bool = False(command line option:-u/--binary/--unicode, environment variable:EMPY_BINARY)If true, open files in binary mode.
inputEncoding: str = 'utf-8'(command line option:--input-encoding=E, environment variable:EMPY_INPUT_ENCODING)The file input encoding to use. This needs to be set before files are opened to take effect.
outputEncoding: str = 'utf-8'(command line option:--output-encoding=E, environment variable:EMPY_OUTPUT_ENCODING)The file output encoding to use. This needs to be set before files are opened to take effect.
inputErrors: str = 'strict'(command line option:--input-errors=E, environment variable:EMPY_INPUT_ERRORS)the file input error handler to use. This needs to be set before files are opened to take effect.
outputErrors: str = 'strict'(command line option:--output-errors=E, environment variable:EMPY_OUTPUT_ERRORS)The file output error handler to use. This needs to be set before files are opened to take effect.
normalizationForm: str = 'NFKC'(command line option:-z/--normalization-form=F)The normalization form to use when applying diacritic combiners. Set to
Noneor''in order to skip normalization.autoPlayDiversions: bool = True(command line option:--no-auto-play-diversions)If diversions are extant when an interpreter is ready to exist, if this variable is true then those diversions will be undiverted to the output stream in lexicographical order by name.
expandUserConstructions: bool = True(command line option:--no-expand-user)If true, when processing configuration files, call
os.path.expanduseron each filename to expand~and~userconstructions.configVariableName: str = '_'(command line option:--config-variable=NAME)When processing configuration files, the existing configuration object can be referenced as a variable. This indicates its name.
successCode: int = 0(command line option:--success-code=N)The exit code to return when a processing is successful.
failureCode: int = 1(command line option:--failure-code=N)The exit code to return when an error occurs during processing.
unknownCode: int = 2(command line option:--unknown-code=N)The exit code to return when a configuration error is found (and processing never starts).
checkVariables: bool = True(command line option:--no-check-variables)If true, configuration variables will be checked to make sure they are known variables and have the proper type on assignment.
pathSeparator: str = ';'(Windows) or':'(others)--path-separator)The path separator to use when specifying multiple filenames with
-c/--config-file=FILENAME. Defaults to;on Windows and:on other platforms.supportModules: bool = True(command line option:-g/--disable-modules)Enable EmPy module support? Requires Python 3.4 or greater.
moduleExtension: str = '.em'(command line option:--module-extension)The filename extension to use for modules.
moduleFinderIndex: int = 0(command line option:--module-finder-index)The integer index where to insert the module finder (required for module support) into the meta path. 0 would insert the finder into the beginning of the meta path (so it is checked before any other finder, such as the native Python module finder), 1 would place it in the second position, etc. A negative index indicates that the finder should be appended to the meta path, so that it is checked last.
enableImportOutput: bool = True(command line option:-j/--disable-import-output)By default output is handled normally when a module is imported; any markup expanded that renders output in a module will be sent to the output stream. This is sometimes undesirable, so this can be disabled by setting this configuration variable to false.
duplicativeFirsts: list[str] = ['(', '[', '{']The list of first markup characters that may be duplicated to indicate variants. For instance,
@(...)is expression markup, but@((...))is parenthesis extension markup.openFunc = NoneThe file open function to use. If
None, defaults to eithercodecs.openoropen, depending on Python version.controls: dict = {...}The controls dictionary used by the named escape markup.
diacritics: dict = {...}The diacritic combiners dictionary used by the diacritic markup.
icons: dict = {...}The icons dictionary used by the icon markup.
emojis: dict = {...}The custom emojis dictionary which is referenced first by the emoji markup. Defaults to an empty dictionary.
See also
The list of configuration variables is available in the variables
help topic and is summarized
here.
New in version 4.0: Configuration objects were introduced in EmPy version 4.0; previously an underused options dictionary was introduced in version 2.2.2.
Configuration methods#
The following methods are supported by configuration instances:
__init__(**kwargs)The constructor. Takes a set of keyword arguments that are then set as attributes in the configuration instance. So
config = em.Configuration(prefix='$')
is a shorter form of
config = em.Configuration() config.prefix = '$'
isInitialized() -> boolHas this instance been initialized? Before initialization, no typechecking is done even if
checkVariablesis set.check(inputFilename: str, outputFilename: str)Check the file settings against these filenames and raise a
ConfigurationErroris there appears to be an inconsistency.has(name: str) -> boolIs this name an existing configuration variable?
get(name: str, [default: object]) -> boolGet the value of this configuration variable or return this default if it does not exist.
set(name: str, value: object)Set the configuration variable to the given value.
update(**kwargs)Set a series of configuration variables via a set of keyword arguments.
clone(deep: bool = False) -> ConfigurationClone this configuration and return it. If
deepis true, make it a deep copy.run(statements: str)Execute a series of configuration commands.
load(filename: str, [required: bool])Load and execute a configuration file. If
requiredis true, raise an exception; if false, ignore; ifNone, use the default for this configuration.path(path: str, [required: bool])Load and execute one or more configuration files separated by the path separator.
requiredargument is the same as forloadabove.hasEnvironment(name: str) -> boolIs the given environment variable defined, regardless of its value?
environment(name: str, [default: str, blank: str])Get the value of the environment variable. If it is not defined, return
default; if it is defined but is empty, returnblank.hasDefaultPrefix() -> boolIs the
prefixconfiguration variable set to the default?has{Full|No|Line|Fixed}Buffering() -> boolIs buffering set to full, none, line, or some fixed value, respectively?
createFactory([tokens: Sequence[Token]]) -> FactoryCreate a token factory from the list of token classes and return it. If
tokensis not specified, use the default list.adjustFactory()Adjust an existing factory to take into account a non-default prefix.
getFactory([tokens: Sequence[Token], [force: bool]])Get a factory, creating one if one has not yet been created, with the given
tokenslist (if not specified, a default list will be used). Ifforceis true, then create a new one even if one already exists.resetFactory()Clear the current factory, if any.
createExtensionToken(first: str, name: str, [last: str])Create a new extension token class with the first character
firstand with method namename. Iflastis specified, use that as the last character; otherwise, guess for a closed form with a default offirst.hasBinary() -> boolIs binary (formerly called Unicode) support enabled?
enableBinary([major: int, minor: int])Enable binary support, conditionally if
majorandminor(the major and minor versions of Python) are specified and binary support is needed for this version of Python.disableBinary()Turn off binary/Unicode support.
isDefaultEncodingErrors([encoding: str, errors: str, asInput: bool]) -> boolAre both the file encoding and file error handler the default? Check for input if
asInputis true, otherwise check for output.getDefaultEncoding([default: str]) -> strGet the current default encoding, overriding with
defaultif desired.open(filename: str, mode: Optional[str] = None, buffering: int = -1, [encoding: Optional[str], errors: Optional[str], expand: bool]) -> fileThe main wrapper around the
open/codecs.opencall, allowing for seamless file opening in both binary and non-binary mode across all supported Python versions.significatorReString() -> strReturn a regular expression string that will match significators in EmPy code with this configuration’s prefix.
Hint
It can be used in Python like this:
data = open('script.em', 'r').read() for result in empy.config.significatorRe().findall(data): string2, key2, value2, string1, key1, value1 = result if key1: print("Single line significator: {} = {}{}".format( key1, value1, ' (stringized)' if string1 else '')) else: # key2 print("Multi-line significator: {} = {}{}".format( key2, value2, ' (stringized)' if string2 else ''))
significatorRe([flags: int]) -> re.PatternReturn a compiled regular expression pattern object for this configuration’s prefix. Override the
reflagsif desired.significatorFor(key: str) -> strReturn the significator variable name for this significator key.
setContextFormat(rawFormat: str)Set the context format for this configuration. See context formatting.
renderContext(context) -> strRender the given context using the existing context format string.
calculateIconsSignature() -> tupleCalculate the icons signature to try to detect any accidental changes.
signIcons()Calculate the icons signature and update the configuration with it.
transmogrifyIcons([icons: dict])Process the icons dictionary and make sure any keys’ prefixes are backfilled with
Nonevalues. This is necessary for the functioning of the icon markup. This method will be called automatically unlessautoValidateIconsis false.validateIcons([icons: dict])Check whether the icons have possibly changed and transmogrify them if necessary.
initializeEmojiModules([moduleNames: Sequence])Scan for existing emoji modules and set up the appropriate internal data structures. Use the list of module names in the configuration if
moduleNamesis not specified.substituteEmoji(text: str) -> strPerform emoji substitution with the detected emoji modules.
isSuccessCode(code: int) -> boolIs this exit code a success code?
isExitError(error: Optional[Error]) -> boolIs this exception instance an exit error rather than a real error?
errorToExitCode(error: Optional[Error]) -> intReturn an appropriate exit code for this error.
isNotAnError(error: Optional[Error]) -> boolDoes this exception instance not represent an actual error?
formatError(error: Optional[Error][, prefix: str, suffix: str]) -> strReturn a string representing the details of the given exception instance, with an optional prefix and suffix.
See also
The list of configuration methods is available in the methods help
topic and is summarized here.
Error handling#
Error dispatchers#
When an error occurs in an EmPy system, first an error dispatcher is invoked. The purpose of the dispatcher is to determine at a high-level what should be done about the error. A dispatcher is a zero-argument callable which primarily determines whether the error should be handled by the running interpreter, whether it should be raise to the parent caller rather than handled by the interpreter, or some other custom behavior.
When specified in the Interpreter constructor or one
of the high-level interpreter methods (e.g., file or string), it
can take on a few special values:
Value |
Meaning |
Corresponding method |
|---|---|---|
|
Use interpreter default |
— |
|
Interpreter should handle error |
|
|
Interpreter should reraise error |
|
Note
For standalone interpreters and its high-level methods, the default
dispatcher is True (dispatch); that is, the interpeter will handle
the error itself. When calling the expand interpreter method or the
global expand function, the dispatcher is False (reraise); in
other words, calls to expand will result in any occurring errors
being raised to the caller rather than handled by the interpteter.
New in version 4.0.1: Error dispatchers were introduced in EmPy version 4.0.1.
Error handlers#
Once an error is dispatched to the interpteter, it is handled by an
error handler. An error handler is a callable object that will
respond to the error and take any necessary action. If no
user-specified error handler is set, the default error handler is
used, which prints a formatted EmPy error message to sys.stderr.
An error handler is a callable object with the following signature:
handler(type, error, traceback) -> bool
It takes the error type, the error instance, and the traceback object
corresponding to an exception (a tuple of which is the return value of
sys.exc_info()) and returns an optional Boolean. If the return
value is true, the default handler will also be invoked after the
error handler is called. (Not explicitly returning anything will
implicitly return None, which is a false value.)
The current error that the interpreter has encountered is set in the
interpreter’s error attribute (with None indicating no error).
The error handler can manually set this attribute to None to clear
the error if desired.
After the error handler(s) have been called, the interpreter will then
decide how to resolve the error. If the error attribute of the
interpreter is still non-None and the configuration variable
exitOnError is true (option: -k/--keep-going), the
interpreter will exit. If the error attribute is None, it will
continue running.
If the ignoreErrors configuration variable (option:
-e/--ignore-errors) is true, then no error dispatchers or error
handlers will be called.
New in version 4.0: Error handlers were introduced in EmPy version 4.0.
Error classses#
The following error classes are used by EmPy:
Class |
Base class |
Meaning |
|---|---|---|
|
|
Base error class |
|
|
An error involving inconsistent settings has occurred |
|
|
A consistency error involving misuse of the stdout proxy |
|
|
An error involving diversions has occurred |
|
|
An error involving filters has occurred |
|
|
An error involving cores has occurred |
|
|
An error involving extensions has occurred |
|
|
A stack has underflowed (internal error) |
|
|
An unknown emoji was requested |
|
|
An old-style string error (used internally) |
|
|
An error invoking the interpreter has occurred |
|
|
An error involving a bad configuration has occurred |
|
|
An error involving backward compatibility has occurred |
|
|
A requested configuration file was missing |
|
|
Invalid EmPy syntax was encountered |
|
|
Invalid EmPy syntax was encountered (but may be resolved by reading further data) |
Reference#
The following reference material is available:
Getting version and debugging information#
To print the version of EmPy you have installed, run:
% em.py -V # or: --version Welcome to EmPy version 4.2.1.
To print additional information including the Python implementation and version, operating system, and machine type, run:
% em.py -W # or: --info Welcome to EmPy version 4.2.1, in CPython/3.10.12, on Linux (POSIX), with x86_64, under GCC/11.4.0.
For diagnostic details (say, to report a potential problem to the developer), run:
% em.py -Z # or: --details Welcome to EmPy version 4.2.1, in CPython/3.10.12, on Linux (POSIX), with x86_64, under GCC/11.4.0. Details: - basic/context: -- - basic/framework/name: GCC - basic/framework/version: 11.4.0 - basic/implementation: CPython - basic/machine: x86_64 ...
Examples and testing#
For quick examples of EmPy code, check out the examples throughout this document. For a more expansive tour of examples illustrating EmPy features, check out tests/sample/sample.em. For a real-world example, check out README.md.em, which is the EmPy source file from which this documentation is generated.
EmPy has an extensive testing system. (If you have EmPy installed via an operating system package that does not include the test system and you wish to use it, download the tarball.)
EmPy’s testing system consists of the shell script test.sh and two directories: tests and suites. The tests directory contains the unit/system tests, and the suites directory contains files with lists of tests to run. The test.sh shell script will run with any modern Bourne-like shell.
Tests can be run changing to the directory where test.sh and both the
tests and suites directories are located, and then executing
./test.sh followed by the tests desired to be run following on the
command line. For example, this runs a quick test:
% ./test.sh tests/sample/sample.em tests/sample/sample.em (python3) [PASS] PASSES: 1/1 All tests passed (python3) in 0.223 s = 223 ms/test.
Specifying a directory will run all the tests contained in that directory and all its subdirectories:
% ./test.sh tests/common/trivial tests/common/trivial/empty.em (python3) [PASS] tests/common/trivial/long.em (python3) [PASS] tests/common/trivial/medium.em (python3) [PASS] tests/common/trivial/short.em (python3) [PASS] tests/common/trivial/short_no_newline.em (python3) [PASS] PASSES: 5/5 All tests passed (python3) in 0.460 s = 92 ms/test.
Suites can be run by using the @ character before the filename. A
suite is a list of tests, one per line, to run. Blank lines and lines
starting with # are ignored:
% cat suites/default # Run tests for Python versions from 3.4 up. tests/common tests/python2.7 tests/python3.4 tests/python3 tests/sample
% ./test.sh @suites/default tests/common/callbacks/deregister.em (python3) [PASS] tests/common/callbacks/get_none.em (python3) [PASS] tests/common/callbacks/get_one.em (python3) [PASS] ... PASSES: 566/566 All tests passed (python3).
To test a version of Python other than the default (that is, other
than a Python 3.x interpreter named python3), specify it with the
-p option to the test script and use that version’s test suite. To
test CPython 2.7, for instance:
% ./test.sh -p python2.7 @suites/python2.7 tests/common/callbacks/deregister.em (python2.7) [PASS] tests/common/callbacks/get_none.em (python2.7) [PASS] tests/common/callbacks/get_one.em (python2.7) [PASS] ...
Suites for all supported interpreters and versions are provided. For example, if you have PyPy 3.10 installed:
% ./test.sh -p pypy3.10 @suites/pypy3.10 tests/common/callbacks/deregister.em (pypy3.10) [PASS] tests/common/callbacks/get_none.em (pypy3.10) [PASS] tests/common/callbacks/get_one.em (pypy3.10) [PASS] ...
To only report errors (“quiet mode”), use the -q option:
% ./test.sh -q @suites/default PASSES: 566/566 All tests passed (python3).
For more information about the testing tool, run:
% ./test.sh -h # or: --help Usage: ./test.sh [<option>...] [--] (<file> | <directory> | @<suite>)... Example: ./test.sh -p python3 @suites/python3 Run one or more EmPy tests, comparing the results to exemplars, and return an exit code indicating whether all tests succeeded or whether there were some failures. If no tests are specified, this help is displayed. Test filenames, directory names, and suite names cannot contain spaces. All tests are run from the current working directory. ...
Note
All tests can be run by specifying tests as the test directory
(./test.sh ... tests) and will automatically skip in the
inappropriate tests; however, specifying the version-specific suite
(e.g., @suites/python3) will be more efficient.
Changed in version 4.0: A simple benchmark test system was introduced in EmPy version 2.1, and was expanded to full unit and system test suites for all supported versions of Python in EmPy version 4.0.
Embedding EmPy#
EmPy can be easily embedded into your Python programs. Simply ensure
that the em.py file is available in the PYTHONPATH and import em
as a module:
import em
print(em)
To embed an interpreter, create an instance of the Interpreter
class. The interpreter constructor requires keyword arguments, all
with reasonable defaults; see here for the list. One
important argument to an interpreter is a
configuration, which, if needed, should be
constructed first and then passed into the interpreter. If no
configuration is specified, a default instance will be created and
used:
import em
config = em.Configuration(...)
interp = em.Interpreter(config=config, ...)
try:
... do some things with interp ...
finally:
interp.shutdown()
Then call interpreter methods on it such as write, evaluate,
execute, expand, string, file, expand, and so on. The full
list of interpreter methods is here.
Exceptions that occur during processing will be handled by the
interpreter’s error handler.
Important
When you create an interpreter, you must call its shutdown method
when you are done. This is required to remove the proxy on
sys.stdout that EmPy requires for proper operation and restore your
Python environment to the state it was before creating the
interpreter. This can be accomplished by creating the interpreter in
a with statement — interpreters are also context managers — or by
creating it and shutting it down in a try/finally statement.
This is not needed when calling the expand global function; it
creates and shuts down an ephemeral interpreter automatically.
Calling the interpreter’s shutdown can be handled with either with a
try/finally statement or a with statement:
import em
interp = em.Interpreter(...)
try:
... do some things with the interpreter ...
finally:
interp.shutdown()
# or ...
with em.Interpreter(...) as interp:
... do other things with the interpreter ...
Warning
If you receive a ProxyError mentioning when quitting your program,
you are likely not calling the shutdown method on the interpreter.
Make sure to call shutdown so the interpreter can clean up after
itself.
Note
The empy pseudmodule is itself an instance
of the Intrerpreter class, and its config attribute is an instance
of the Configuration class, so within an EmPy interpreter you can
access the Interpreter and Configuration classes without needing
to import the em module:
@{
Configuration = empy.config.__class__
Interpreter = empy.__class__
config = Configuration(...)
interp = Interpreter(config=config, ...)
...
}@
There is also a global expand function which will expand a single
string and return the results, creating and destroying an ephemeral
interpreter to do so. You can use this function to do a one-off
expansion of, say, a large file:
import em
data = open('tests/sample/sample.em').read()
print(em.expand(data))
If an exception occurs during expand processing, the exception will
be raised to the caller.
Standard modules#
A fully-functional EmPy system contains the following standard modules.
empy pseudomodule#
The pseudomodule is not an actual module, but rather the instance of the running EmPy interpreter exposed to the EmPy system. It is automatically placed into the interpreter’s globals and cannot be imported explicitly. See Pseudomodule/interpreter for details.
em module#
The primary EmPy module. It contains the Configuration and
Interpreter classes as well as all supporting logic. An EmPy system
can be functional with only this module present if needed.
It also includes the following global functions:
details(level, [prelim, postlim, file])Write details about the running system to the given file, which defaults to
sys.stdout. Thelevelparameter is an attribute of theem.Versionclass (effectively an enum).prelimandpostlimindicate preliminary and postliminary text to output before and after the details (and have reasonable defaults).Note
This function requires the
emlibstandard module to be installed to function most effectively.
expand(data, **kwargs) -> strCreate a ephemeral interpreter with the given kwargs, expand data, shut the interpreter down, and then return the expansion. The function takes the same keyword arguments as the
Interpreterconstructor, with the following additions:Argument
Meaning
Default
dispatcherDispatch errors or raise to caller?
FalselocalsThe locals dictionary
{}nameThe context filename
"<expand>"If the markup that is being expanded causes an exception to be raised, by default the exception will be let through to the caller.
Important
As with the
Interpreterconstructor, the order of theexpandarguments has changed over time and is subject to change in the future, so you must use keyword arguments to prevent any ambiguity, e.g.:myConfig = em.Configuration(...) myGlobals = {...} myOutput = open(...) result = em.expand(source, config=myConfig, globals=myGlobals, ...)
Attempts have been made to make the
expandfunction as backward compatible (to 3.x) as feasible, but some usages are ambiguous or do not have direct mappings to configurations. ACompatibilityErrorwill be raised in these cases; if you encounter this, redesign your use ofexpandto be compatible with the modern usage. In particular, in 3.x, additional keyword arguments were used to indicate the locals dictionary; in 4.x, keyword arguments are used for all arguments so the locals dictionary must be specified as a distinctlocalskeyword argument:myGlobals = {...} myLocals = {...} result = em.expand(source, globals=myGlobals, locals=myLocals)
Warning
Not all of the
Interpreterconstructor arguments are compatible with theexpandfunction. Thefilters,handler,inputandoutputarguments are immediately overridden by the inherent nature of the ephemeral interpreter and so would not behave as expected. Thus, if they are specified, aConfigurationErrorwill be raised. For more detailed configuration of an interpreter, it’s better to create one yourself rather than rely onexpand.
invoke(args, **kwargs)Invoke the EmPy system with the given command line arguments (
sys.argv[1:], notsys.argv) and optional string settings. This is the entry point used by the main EmPy function. The remaining keyword arguments correspond to theInterpreterconstructor arguments.Warning
Since the
invokefunction configures and manages the lifetime of anInterpreter, not all of the constructor arguments are compatible with it. Specifically, thefilespecandimmediatelyarguments need to be managed by the function and so specifying a starting value is nonsensical. Thus, if they are specified, aConfigurationErrorwill be raised.
emlib module#
The EmPy supporting library. It contains various support classes,
including the base classes Filter and Hook to assist in creating
this supporting functionality.
emhelp module#
The EmPy help system. It can be accessed from the main executable
with the -h/--help and -H/--topics=TOPICS command
line options. If the emlib module is not available to the executable,
the help system will return an error.
emdoc module#
The EmPy documentation system, used to create this document.
Note
Unlike the other EmPy modules, emdoc requires a modern Python 3.x
interpreter.
Using EmPy with build tools#
If you’re using EmPy to process documents within a build system such
as GNU Make or Ninja, you’ll want to use the -o/--output=FILENAME (or
-a/--append=FILENAME) and -d/--delete-on-error options together. This
will guarantee that a file will be output (or appended) to a file
without shell redirection, and that the file will be deleted if an
error occurs. This will prevent errors from leaving a partial file
around which subsequent invocations of the build system will mistake
as being up to date. The invocation of EmPy should look like this
(the -- is not required if the input filename never starts with a
dash):
em.py -d -o $output -- $input
For GNU Make:
EMPY ?= em.py
EMPY_OPTIONS ?= -d
%: %.em
$(EMPY) $(EMPY_OPTIONS) -o $@ -- $<
For Ninja:
empy = em.py
empy_options = -d
rule empy
command = $empy $empy_options -o $out -- $in
Context formatting#
Contexts are objects which contain the filename, the line number, the column number, and the character (Unicode code point) number to record the location of an EmPy error during processing.
These are formatted into human-readable strings with a context
format, a string specifiable with --context-format (configuration variable: contextFormat). A few different mechanisms for formatting contexts are
available:
Mechanism |
Description |
Example |
|---|---|---|
format |
Use the |
|
operator |
Use the |
|
variable |
Use |
|
The default context format is %(name)s:%(line)d:%(column)d and
uses the operator mechanism for backward compatibility.
When a context format is set, EmPy will attempt to detect which of the above mechanisms is needed:
Mechanism |
Criteria |
|---|---|
format |
string begins with |
operator |
string begins with |
variable |
string begins with |
Data flow#
input ⟶ interpreter ⟶ diversions ⟶ filters ⟶ output
Here, in summary, is how data flows through a working EmPy system:
Input comes from a source, such as an .em file on the command line,
sys.stdin, a module import, or via anempy.includestatement.The interpreter processes this material as it comes in, processing EmPy expansions as it goes.
After expansion, data is then sent through the diversion layer, which may allow it directly through (if no diversion is in progress) or defer it temporarily. Diversions that are recalled initiate from this point.
If output is disabled, the expansion is dropped.
Otherwise, any filters in place are then used to filter the data and produce filtered data as output.
Finally, any material surviving this far is sent to the output stream. That stream is
sys.stdoutby default, but can be changed with the-o/--output=FILENAMEor-a/--append=FILENAMEoptions.If an error occurs, execute the error handler (which by default prints an EmPy error). If the
-r/--raw-errorsoption is specified, then print a full Python traceback. If-k/--keep-goingis specified, continue processing rather than exit; otherwise halt.On unsuccessful exit, if
-d/--delete-on-erroris specified, delete any specified output file.
Glossary#
The following terms with their definitions are used by EmPy:
- callback
The user-provided callback which is called when the custom markup
@<...>is encountered. Custom markup and callbacks have been supplanted by extensions.- command
A processing step which is performed before or after main document processing. Examples are
-D/--define=DEFN,-F/--file=FILENAMEor-P/--preprocess=FILENAME.- configuration
An object encapsulating all the configurable behavior of an interpreter which passed into interpreter on creation. Configurations can be shared between multiple interpreters.
- context
An object which tracks the location of the parser in an EmPy file for tracking and error reporting purposes.
- control markup
A markup used to direct high-level control flow within an EmPy session. Control markups are expressed with the
@[...]notation.- core
An interpreter core is a plugin which determines how the underlying language is evaluated, executed, serialized, and how the
@[def ...]control markup works. By default, the underlying language is Python.- custom markup
The custom markup invokes a callback which is provided by the user, allowing any desired behavior. Custom markup is
@<...>. Custom markup and callbacks have been supplanted by extensions.- diacritic
A markup which joins together a letter and one or more combining characters from a dictionary in the configuration and outputs it. Diacritic markup is
@^....- dispatcher
An error dispatcher determines whether to dispatch the error to the interpreter’s error handler (
True), to reraise the error to the caller (False), or something else.- diversion
A process by which output is deferred, and can be recalled later on demand, multiple times if desired.
- document
An EmPy file containing EmPy markup to expand.
- embedding
Using an EmPy system by importing the
emmodule and using the API to create and manipulate interpreters programmatically, as opposed to standalone.- emoji
A markup which looks up a Unicode code point by name via a customizable set of installable emoji modules, or via a dictionary in the configuration. Emoji markup is
@:...:.- error
An exception thrown by a running EmPy system. When these occur, they are dispatched by an error dispatcher and then (possibly) passed to an error handler.
- escape
A markup designed to expand to a single (often non-printable) character, similar to escape sequences in C or other languages. Escape markup is
@\....- executable
The Python executable for an EmPy system, which by default is em.py.
- expansion
The process of processing EmPy markups and producing output.
- expression
An expression markup represents a Python expression to be evaluated, and replaced with the
strof its value. Expression markup is@(...).- extension
An interpreter extension is a plugin which defines user-specifiable custom markups.
- file
An object which exhibits a file-like interface (methods such as
writeandclose).- filter
A file-like object which can be chained to other filters or the final stream, and can buffer, alter, or manipulate in any way the data sent. Filters can be chained together in arbitrary order.
- finalizer
A function which is called when an interpreter exits. Multiple finalizers can be added to each interpreter.
- finder
The
importlibarchitecture for importng custom modules uses the meta path (sys.meta_path) which consists of a list of module finders to use. EmPy installs its own finder in this meta path for EmPy module support.- globals
The dictionary (or dictionary-like object) which resides inside the interpreter and holds the currently-defined variables.
- handler
An error handler which is called whenever an error occurs in the EmPy system. The default error handler prints details about the error to
sys.stderr.- hook
A callable object that can be registered in a dictionary, and which will be invoked before, during, or after certain internal operations, identified by name with a string. Some types of hooks can override the behavior of the EmPy interpreter.
- icon
A markup which looks up a variable-length abbreviation for a string from a lookup table in the configuration. Icon markup is
@|....- interpreter
The application (or class instance) which processes EmPy markup.
- locals
Along with the globals, a locals dictionary can be passed into individual EmPy API calls.
- markup
EmPy substitutions set off with a prefix (by default
@) and appropriate delimiters.- module
An EmPy module, imported with the native Python
importstatement.- named escape
A control character referenced by name in an escape markup,
@\^{...}.- output
The final destination of the result of processing an EmPy file.
- plugin
An object which can be attached to an interpreter for custom functionality and implicitly retains a reference to it. Examples are cores and extensions.
- prefix
The Unicode code point (character) used to set off an expansions. By default, the prefix is
@. If set toNone, no markup will be processed.- processor
An extensible system which processes a group of EmPy files, usually arranged in a filesystem, and scans them for significators.
- proxy
An object which replaces the
sys.stdoutfile object and allows the EmPy system to intercept any indirect output tosys.stdout(say, by theprintfunction).- pseudomodule
The module-like object named
empy(by default) which is exposed as a global inside every EmPy system. The pseudomodule and the interpreter are in fact the same object, an instance of theInterpreterclass.- recode
Converting reference values representing strings (contained in the dictionaries corresponding to
emojis,icons,diacriticsorcontrols) into native strings for expansion.- shortcut
An abbreviation that can be used in the
-I/--import=MODULEScommand line option; e.g.,--import sys:version=verforfrom sys import version as ver.- significator
A special form of an assignment markup in EmPy which can be easily parsed externally, primarily designed for representing uniform assignment across a collection of files. Significator markup is
@%[!]... NLand@%%[!]...%% NL.- standalone
Using the EmPy system by running the
em.pyexecutable from the command line.- statement
A line of code that needs to be executed; statements do not have return values. Statement markup is
@{...}.- stream
A file-like object which manages diversion and filtering. A stack of these is used by the interpreter with the top one being active.
- system
A running EmPy environment.
- token
An element of EmPy parsing. Tokens are parsed and then processed one at a time.
Statistics#
% wc emdoc.py emhelp.py timeline.py emlib.py em.py test.sh LICENSE.md README.md README.md.em
551 1519 18487 emdoc.py
1080 4944 47843 emhelp.py
291 932 8404 timeline.py
1345 4013 43224 emlib.py
7032 24918 262309 em.py
923 3139 23555 test.sh
14 230 1520 LICENSE.md
8244 35329 247737 README.md
7605 35614 250472 README.md.em
27085 110638 903551 total
% sha1sum emdoc.py emhelp.py timeline.py emlib.py em.py test.sh LICENSE.md README.md README.md.em 7821817cbb6d55a5e14a5d250913d5a7f813ddf9 emdoc.py 1e18843ff150236f4d0a22d85814440c6257a83d emhelp.py eda8b74776467e9e160722c9be198770d13ea8c5 timeline.py c8cc5e34c26beab4c438d3b9878b9da44d0added emlib.py a43d49fd854f68a2047e77013384f1139775d12f em.py 4a54d29cf0a87d2d350d6c44d05d00c0c2eed3a2 test.sh b6db0b81a7c250442f29dcf8530c032b33662a95 LICENSE.md 9c686e247688003f4bf1d8b0470ac2a121b1e930 README.md 28f1f1dee6d3f31d9c2a71702be53188b25532c0 README.md.em
End notes#
Acknowledgements#
Questions, suggestions, bug reports, evangelism, and even complaints from many people over the years have helped make EmPy what it is today. Some, but by no means all, of these people are (in alphabetical order by surname):
Biswapesh Chattopadhyay
Beni Cherniavsky
Dr. S. Candelaria de Ram
Eric Eide
Dinu Gherman
Grzegorz Adam Hankiewicz
Robert Kroeger
Bohdan Kushnir
Kouichi Takahashi
Ville Vainio
Known issues and caveats#
A running EmPy system is just an alternate form of a Python interpreter; EmPy code is just as powerful as any Python code. Thus it is vitally important that an EmPy system not expand EmPy markup from an untrusted source; this is just as unsafe and potentially dangerous as executing untrusted Python code.
As the EmPy parser is written in Python, it is not designed for speed. A compiled version designed for speed may be added in the future.
To function properly, EmPy must override
sys.stdoutwith a proxy file object, so that it can capture output of side effects and support diversions for each interpreter instance. It is important that code executed in an environment not rebindsys.stdout, although it is perfectly legal to reference it explicitly (e.g.,@sys.stdout.write("Hello world\n")). If one really needs to access the “true” stdout, then usesys.__stdout__instead (which should also not be rebound). EmPy uses the standard Python error handlers when exceptions are raised in EmPy code, which print tosys.stderr.sys.stderr,sys.__stdout__, andsys.__stderr__are never overridden by the interpreter; onlysys.stdoutis.If you are using multiple interpreters with distinct output files and are using the low-level interpreter methods (the ones not documented here) to perform expansion and output, the
sys.stdoutproxy will not be reliable. Only the high-level interpreter methods (evaluate,execute,string,expand) properly use the protected stream stack on thesys.stdoutproxy to guarantee valid output. Either only use a single interpreter instance at a time (creating and shutting it down with itsshutdownmethod), use the-n/--no-proxyoption and only perform output with thewritemethod on the interpreter (i.e., do not use anyprintstatements in your code), or only use the high-level interpreter methods documented here.The
empy“module” exposed through the EmPy interface (i.e.,@empy) is an artificial module. It is automatically exposed in the globals of a running interpreter and it cannot be manually imported with theimportstatement (nor should it be — it is an artifact of the EmPy processing system and does not correspond directly to any .py file).For an EmPy statement expansion all alone on a line, e.g.,
@{a = 1}, will include a blank line due to the newline following the closing curly brace. To suppress this blank line, use the symmetric convention@{a = 1}@, where the final@markup precedes the newline, making it whitespace markup and thus consumed. For instance:@{a = 1} There will be an extra newline above (following the closing brace). Compare this to: @{a = 1}@ There will be no extra newline above.See here for more details.
Errors generated from within nested control structures (e.g.,
@[for ...]@[if ...]...@[end if]@[end for]will report a context of the start of the top-level control structure markup, not the innermost markup, which would be much more helpful. This issue is not new to 4.0 and will be addressed in a future release.Errors are very literal and could be made more useful to find the underlying cause.
Contexts (such as
empy.identify) track the context of executed EmPy code, not Python code. This means, for instance, that blocks of code delimited with@{and}will identify themselves as appearing on the line at which the@{appears. If you’re tracking errors and want more information about the location of the errors from the Python code, use the-r/--raw-errorsoption, which will provide you with the full Python traceback.The
@[for]variable specification supports tuples for tuple unpacking, even recursive tuples. However, it is limited in that the names included may only be valid Python identifiers, not arbitrary Python “lvalues.” Since this is something of an accidental Python feature that is very unlikely to be relied on in practice, this is not thought to be a significant limitation. As a concrete example:a = [None] for a[0] in range(5): print(a)
is valid (but strange) Python code, but the EmPy equivalent with
@[for a[0] in range(5)]...is invalid.The
:=assignment expression syntax (“walrus operator”) forwhileloops andifstatements, introduced in Python 3.8, is not supported in the EmPy equivalent control markups@[while]and@[if]. This may be supported in the future.As of Python 3.10, the
withcontrol structure supports specifying multiple context managers separated by commas. This is not yet supported by EmPy, but may be in a future version. For now, just use nested@[with]control markups.
For package maintainers#
EmPy is available as a system package in most major Linux distributions, though some have not updated to EmPy 4.x yet.
EmPy can be made available as an operating system distribution package
in several different ways. Regardless of the high-level organization,
the installed .py Python files must be made available as importable
Python modules, with the additional requirement that em.py must be
made available as an executable in the default PATH. If necessary,
this executable may also be named empy, but em.py is preferred —
and either way it is still important that the em.py file be available
for importing as a Python module (em).
Important
Since EmPy 4.x is not fully compatible with EmPy 3.x, I suggest making both EmPy 3.x and 4.x packages available side by side until 4.x becomes more fully adopted by the community.
Here is a breakdown of the contents of a release tarball:
File |
Description |
|---|---|
em.py |
Main EmPy module and executable |
emhelp.py |
Help subsystem module |
emlib.py |
Supplementary EmPy facilities module |
emdoc.py |
Documentation subsystem module |
setup.py |
|
ANNOUNCE.md |
EmPy 4.x release announcement |
HELP.md |
Help topic summaries |
LEGACY.md |
Legacy user’s guide (3.3.4) |
LICENSE.md |
Software license |
README.md |
README (this file) |
README.md.em |
README source file |
doc |
HTML documentation directory hierarchy |
test.sh |
Test shell script |
tests |
Tests directory hierarchy |
suites |
Test suites directory hierarchy |
They can either be bundled up into a single, monolithic package, or divided into a series of subpackages. Here’s a suggestion for a fleshed-out series of EmPy subpackages:
empy-minimalJust the em.py file, available as a Python module as well as an executable. Note that this will not allow the use of the EmPy help subsystem, unless the module emhelp.py is also included.
empy-basicThe .md files, all the .py files (em.py, emhelp.py, emlib.py, emdoc.py) available as Python modules, with the em.py file also available as an executable.
empy-docThe docs directory hierarchy, the top-level .md files (README.md, LICENSE.md, etc.) and the README EmPy source file README.md.em.
empy-testThe test script test.sh, the tests directory, and the suites directory.
empyAll of the above.
Reporting bugs#
If you find a bug in EmPy, please follow these steps:
Whittle a reproducible test case down to the smallest standalone example which demonstrates the issue, the smaller the better;
Collect the output of
em.py -Z(this will provide detailed diagnostic details about your environment), or at leastem.py -W(which provides only basic details);Send me an email with EmPy in the Subject line including both files and a description of the problem.
Thank you!
Release history#
- 4.2.1 (2026 Feb 8)
codecs.openis deprecated as of Python 3.14, so useopeninstead in binary mode; better proxy and module finder management usingsysmodule; uniform attachment and detachment of plugins; converted and expanded documentation to Furo theme; better Java exception printing under Jython; add preinitializers, postinitialiers, and requirements for testing; additions to named escapes; addSimpleTokentoken factory.- 4.2 (2024 Aug 25)
Add module support; add support for disabling output and switch markup; add support for reconfiguring stdin/stdout; support repeated curly braces with functional expression; add backward-compatible
Caseabstraction for match markup; add more preprocessing and postprocessing commands via command line options (-K/--postexecute=STATEMENT,-X/--expand=MARKUP,-Y/--postexpand=MARKUP).
- 4.1 (2024 Mar 24)
Add support for extension markup
@((...)),@[[...]],@{{...}},@<...>, etc., with custom callbacks retained for backward compatibility; add@[match]control support; add interpreter cores for overriding interpreter behavior; add more command line option toggles; add notion of verbose/brief errors; more uniform error message formatting; various documentation updates.
- 4.0.1 (2023 Dec 24)
Add root context argument, serializers, and idents to interpreter; fix
setContext...methods so they also modify the currents stack; better backward compatibility forexpandfunction andCompatibilityError; fix inconsistent stack usage withexpandmethod; add error dispatchers, cleaner error handling andignoreErrors; haveexpandmethod/function raise exceptions to caller; eliminate need forFullContextclass distinct fromContext; support comments in “clean” controls; add--no-none-symboloption; add clearer errors for removed literal markup; addContainersupport class inemlib; hide non-standard proxy attributes and methods; support string errors (why not); update and expand tests; help subsystem and documentation updates.
- 4.0 (2023 Nov 29)
A major revamp, refresh, and modernization. Major new features include inline comments
@*...*; backquote literals@`...`; chained if-then-else expressions; functional expressions@f{...}; full support for@[try],@[while ...]and@[with ...]control markup;@[defined ...]control markup; stringized and multiline significators; named escapes@\^{...}; diacritics@^...; icons@|...; emojis@:...:; configurations; full Unicode and file buffering support; proxy now reference counted; hooks can override behavior; many bug fixes; an extensive builtin help system (emhelp); and rewritten and expanded documentation in addition to a dedicated module (emdoc). Changes include relicensing to BSD, interpreter constructor now requires keyword arguments,-d/--delete-on-errorinstead of “fully buffered files”; cleaned up environment variables; “repr” markup replaced with emoji markup; remove literal markups@),@],@}; context line markup@!...no longer pre-adjusts line; custom markup@<...>now parsed more sensibly; filter shortcuts removed; context now track column and character count; auxiliary classes moved toemlibmodule; useargvinstead ofargcfor interpreter arguments. See Full list of changes between EmPy 3.x and 4.0 for a more comprehensive list.
- 3.3.4a (2021 Nov 19)
Fix an error in setup.py in the release tarball (did not affect PIP downloads).
- 3.3.4 (2019 Feb 26)
Minor fix for a Python 3.x compatibility issue.
- 3.3.3 (2017 Feb 12)
Fix for
empy.definedinterpreter method.- 3.3.2 (2014 Jan 24)
Additional fix for source compatibility between 2.x and 3.0.
- 3.3.1 (2014 Jan 22)
Source compatibility for 2.x and 3.0; 1.x compatibility dropped.
- 3.3 (2003 Oct 27)
Custom markup
@<...>; remove separate pseudomodule instance for greater transparency; deprecateInterpreterattribute of pseudomodule; deprecate auxiliary class name attributes associated with pseudomodule in preparation for separate support library in 4.0; add--no-callback-error[defunct] and--no-bangpath-processing[now--no-ignore-bangpaths] command line options; addatTokenhook.- 3.2 (2003 Oct 7)
Reengineer hooks support to use hook instances; add
-v/--verboseand-l/--relative-pathoption; reversed PEP 317 style; modify Unicode support to give less confusing errors in the case of unknown encodings and error handlers; relicensed under LGPL.- 3.1.1 (2003 Sep 20)
Add string literal
@"..."markup; add-w/--pause-at-endoption; fix improper globals collision error via thesys.stdoutproxy.- 3.1 (2003 Aug 8)
Unicode support (Python 2.0 and above); add Document and Processor helper classes for processing significators [later moved to
emlib]; add--no-prefixoption for suppressing all markups.- 3.0.4 (2003 Aug 7)
Implement somewhat more robust “lvalue” parsing for
@[for]construct.- 3.0.3 (2003 Jul 9)
Fix bug regarding recursive tuple unpacking using
@[for]; addempy.saveGlobals,empy.restoreGlobals, andempy.definedfunctions.- 3.0.2 (2003 Jun 19)
@?and@!markups for changing the current context name and line, respectively; addupdatemethod to interpreter; new and renamed context operations,empy.setContextName,empy.setContextLine,empy.pushContext,empy.popContext.- 3.0.1 (2003 Jun 9)
Fix simple bug preventing command line preprocessing directives (
-I/--import=MODULES,-D/--define=DEFN,-E/--execute=STATEMENT,-F/--file=FILENAME,-P/--preprocess=FILENAME) from executing properly; defensive PEP 317 compliance [defunct].- 3.0 (2003 Jun 1)
Replace substitution markup with control markup
@[...]; support@(...?...!...)for conditional expressions; add acknowledgements and glossary sections to documentation; rename buffering option back to-b/--buffering; add-m/--pseudomodule=NAMEand-n/--no-proxyfor suppressingsys.stdoutproxy; rename main error class toError; add standaloneexpandfunction; add--binaryand--chunk-sizeoptions [defunct]; reengineer parsing system to use tokens for easy extensibility; safeguard curly braces in simple expressions [now used by functional expressions]; fix bug involving customInterpreterinstances ignoring globals argument;distutils[nowsetuptools] support.- 2.3 (2003 Feb 20)
Proper and full support for concurrent and recursive interpreters; protection from closing the true stdout file object; detect edge cases of interpreter globals or
sys.stdoutproxy collisions; add globals manipulation functionsempy.getGlobals,empy.setGlobals, andempy.updateGlobalswhich properly preserve theempypseudomodule; separate usage info out into easily accessible lists for easier presentation; have-hoption show simple usage and-Hshow extended usage [defunct]; addNullFileutility class.- 2.2.6 (2003 Jan 30)
Fix a bug in the
Filter.detachmethod (which would not normally be called anyway).- 2.2.5 (2003 Jan 9)
Strip carriage returns out of executed code blocks for DOS/Windows compatibility.
- 2.2.4 (2002 Dec 23)
Abstract Filter interface to use methods only; add
@[noop: ...]substitution for completeness and block commenting [defunct].- 2.2.3 (2002 Dec 16)
Support compatibility with Jython by working around a minor difference between CPython and Jython in string splitting.
- 2.2.2 (2002 Dec 14)
Include better docstrings for pseudomodule functions; segue to a dictionary-based options system for interpreters; add
empy.clearAllHooksandempy.clearGlobals; include a short documentation section on embedding interpreters; fix a bug in significator regular expression.- 2.2.1 (2002 Nov 30)
Tweak test script to avoid writing unnecessary temporary file; add
Interpreter.singlemethod; exposeevaluate,execute,substitute[defunct], andsinglemethods to the pseudomodule; add (rather obvious)EMPY_OPTIONSenvironment variable support; addempy.enableHooksandempy.disableHooks; include optimization to transparently disable hooks until they are actually used.- 2.2 (2002 Nov 21)
Switched to
-V/--versionoption for version information;empy.createDiversionfor creating initially empty diversion; direct access to diversion objects withempy.retrieveDiversion; environment variable support; removed--rawlong argument (use-r/--raw-errorsinstead); added quaternary escape code (well, why not).- 2.1 (2002 Oct 18)
Finalizers now separate from hooks; include a benchmark sample and test.sh verification script; expose
empy.stringdirectly;-D/--define=DEFNoption for explicit defines on command line; remove ill-conceived support for@else:separator in@[if ...]substitution [defunct]; handle nested substitutions properly [defunct];@[macro ...]substitution for creating recallable expansions [defunct]; add support for finalizers withempy.atExit[nowempy.appendFinalizer].- 2.0.1 (2002 Oct 8)
Fix missing usage information; fix
after_evaluatehook not getting called [defunct].- 2.0 (2002 Sep 30)
Parsing system completely revamped and simplified, eliminating a whole class of context-related bugs; builtin support for buffered filters; support for registering hooks; support for command line arguments; interactive mode with
-i/--interactive; significator value extended to be any valid Python expression.- 1.5.1 (2002 Sep 24)
Allow
@]to represent unbalanced close brackets in@[...]markups [defunct].- 1.5 (2002 Sep 18)
Escape codes (
@\...); conditional and repeated expansion substitutions [defunct; replaced with control markups]; fix a few bugs involving files which do not end in newlines.- 1.4 (2002 Sep 7)
Add in-place markup
@:...:...:[now@$...$...$]; fix bug with triple quotes; collapse conditional and protected expression syntaxes into the single generalized@(...)notation;empy.setNameandempy.setLinefunctions [nowempy.setContextNameandempy.setContextLine]; true support for multiple concurrent interpreters with improvedsys.stdoutproxy; proper support forempy.expandto return a string evaluated in a subinterpreter as intended; reorganized parser class hierarchy.- 1.3 (2002 Aug 24)
Pseudomodule as true instance; move toward more verbose (and clear) pseudomodule function names; fleshed out diversions model; filters; conditional expressions; except expressions; preprocessing with
-P/--preprocess=FILENAME.- 1.2 (2002 Aug 16)
Treat bangpaths as comments;
empy.quotefor the opposite process ofempy.expand; significators (@%...sequences); add-I/--import=MODULESand-f/--flattenoptions; much improved documentation.- 1.1.5 (2002 Aug 15)
Add a separate
invokefunction that can be called multiple times with arguments to execute multiple runs.- 1.1.4 (2002 Aug 12)
Handle strings thrown as exceptions properly; use
getoptto process command line arguments; cleanup file buffering withAbstractFile[defunct]; very slight documentation and code cleanup.- 1.1.3 (2002 Aug 9)
Support for changing the prefix from within the
empypseudomodule [defunct; now in configuration].- 1.1.2 (2002 Aug 5)
Renamed buffering option [defunct], added
-F/--file=FILENAMEoption for interpreting Python files from the command line, fixed improper handling of exceptions from commands (-E/--execute=STATEMENT,-F/--file=FILENAME).- 1.1.1 (2002 Aug 4)
Typo bugfixes; documentation clarification.
- 1.1 (2002 Aug 4)
Added option for fully buffering output [defunct; use
-d/--delete-on-errorinstead], executing commands through the command line; some documentation errors fixed.
- 1.0 (2002 Jul 23)
Renamed project to EmPy. Documentation and sample tweaks; added
empy.flatten[nowempy.flattenGlobals]; added-a/--append=FILENAMEoption. First official release.- 0.3 (2002 Apr 14)
Extended “simple expression” syntax, interpreter abstraction, proper context handling, better error handling, explicit file inclusion, extended samples.
- 0.2 (2002 Apr 13)
Bugfixes, support non-expansion of
Nones, allow choice of alternate prefix.- 0.1.1 (2002 Apr 12)
Bugfixes, support for Python 1.5.x [defunct], add
-r/--raw-errorsoption.
- 0.1 (2002 Apr 12)
Initial early access release.
Timelines#
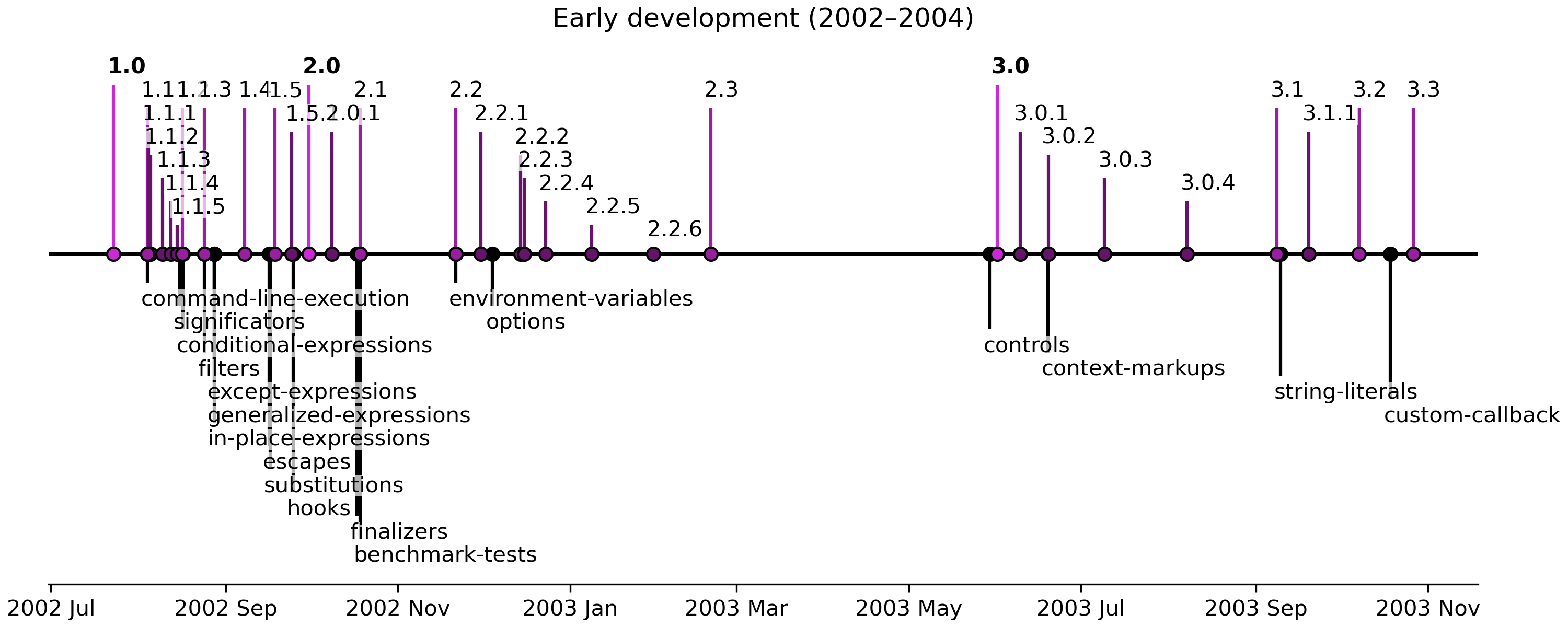
Contact#
This software was written by Erik Max Francis. If you use this software, have suggestions for future releases, or bug reports or problems with this documentation, I’d love to hear about it.
Even if you try out EmPy for a project and find it unsuitable, I’d like to know what stumbling blocks you ran into so they can potentially be addressed in a future version.
I hope you enjoy using EmPy! ℰ
About this document#
This document was generated with EmPy itself using the emdoc module.
Both the source (README.md.em) and the resulting Markdown text
(README.md) are included in the release tarball, as is the HTML
directory hierarchy generated with Sphinx (doc).
This documentation for EmPy version 4.2.1 was generated from README.md.em (SHA1 28f1f1dee6d3f31d9c2a71702be53188b25532c0, 250472 bytes) at 2026-03-18 19:18:55 using EmPy version 4.2.1, in CPython/3.10.12, on Linux (POSIX), with x86_64, under GCC/11.4.0.
Comment markup#
Comment markup consumes its contents and performs no output. A few variants of comment markup are available.
Line comment markup:
@#... NL#Line comment markup consists of a starting
@#and consumes up until (and including) the following newline. Note that if the markup appears in the middle of a line, that line will be continued since it consumes the ending newline.Example 6: Line comments
Source: ⌨️
Output: 🖥️
New in version 1.0: Line comment markup was introduced in EmPy version 1.0.
Inline comment markup:
@*...*#Inline comment markup (
@*...*) is a form of comment markup that can appear anywhere in text and can even span multiple lines. It consumes everything up to and including the final asterisk(s).Example 7: Inline comments, basic
Source: ⌨️
Output: 🖥️
Multiple asterisks can be used as long as they are matched with the end of the markup. This allows asterisks to appear in the comment, provided there are fewer asterisks than the delimiters:
Example 8: Inline comments, advanced
Source: ⌨️
@** Here's an asterisk inside the comment: * **@ @*** There can * be any number of asterisks ** as long as it's * less than ** the delimiters. ***@ @** * This is a multiline inline comment. **@ @************************************* * This comment thinks it's so cool. * *************************************@ So many comments!Output: 🖥️
Attention
Note that when markup which has starting and ending delimiters appears alone on a line, the trailing newline will be rendered in the output. To avoid these extra newlines, use a trailing
@to turn it into whitespace markup which consumes that trailing newline, so e.g.@*...*followed by a newline becomes@*...*@followed by a newline. This is idiomatic for suppressing unwanted newlines. See here for more details.New in version 4.0: Inline comment markup was introduced in EmPy version 4.0.
Whitespace markup:
@ WS#While not quite a comment, whitespace markup is sufficiently common and useful that it warrants introduction early on. The interpreter prefix followed by any whitespace character, including a newline, is consumed. This allows a way to concatenate two strings, create a line continuation, or create a line separator:
Example 9: Whitespace, basic
Source: ⌨️
Output: 🖥️
Tip
A trailing prefix after markup which has beginning and ending delimiters — for instance, inline comment (
@*...*), expression (@(...)), statement (@{...}) and control (@[...]) — is idiomatic for suppressing the newline when there is nothing at the end of the line after the markup. The trailing prefix will consume the final newline, eliminating unwanted newlines.For example, using a statement markup (see below) on a whole line will result in a seemingly spurious newline:
Example 10: Whitespace, idiom
Source: ⌨️
Output: 🖥️
New in version 1.0: Whitespace markup was introduced in EmPy version 1.0.
Switch markup#
Output to the underlying file can be switched on and off with output switch markup. This can be useful, for instance, when sourcing a file that is a “header” or “module” which defines various objects but its output is irrelevant; you can disable output at the beginning of the file and enable it at the end to ensure that any output is ignored. By default, output is enabled.
Both markups consume everything up to and including the next newline, effectively acting as a comment analogous to
@#.The markup is very simple.
New in version 4.2: Switch markups were introduced in EmPy version 4.2.
Switch disable markup:
@-... NL#A line starting with
@-is switch disable markup and will disable output. The entire line is consumed.Example 11: Output disable
Source: ⌨️
Output: 🖥️
Switch enable markup:
@+... NL#A line starting with
@+is switch enable markup and will (re-)enable output. The entire line is consumed.For example:
Example 12: Output disable and enable
Source: ⌨️
Output: 🖥️
Note
Diversions attempt to write their contents to the output stream only when they are played (or replayed), not when they are created. Thus, you can create diversions when output is disabled just fine:
Example 13: Output switches: diversions
Source: ⌨️
Output: 🖥️
Literal markups
Literal markups are a category of markup that evaluate to some form of themselves.
Prefix markup:
@@To render the prefix character literally in the output, duplicate it as prefix markup. For the default,
@, it will be@@:Example 14: Prefix literals
Source: ⌨️
Output: 🖥️
Tip
The prefix markup is not indicated by the prefix followed by an at sign, but rather the prefix repeated once. So if the prefix has been changed to
$, the prefix markup is$$, not$@.New in version 1.0: Prefix markup was introduced in EmPy version 1.0.
String markup:
@'...',@"...",@'''...''',@"""..."""#The interpreter prefix followed by a Python string literal (e.g.,
@'...') is string markup. It evaluates the Python string literal and expands it. All variants of string literals with single and double quotes, as well as triple quoted string literals (with both variants) are supported. This can be useful when you want to use Python string escapes (not EmPy escapes) in a compact form:Example 15: String
Source: ⌨️
Output: 🖥️
New in version 3.1.1: String markup was introduced in EmPy version 3.1.1.
Backquote markup:
@`...`#Backquote markup (
@`...`) can be used to escape any text, including EmPy markup. Multiple opening backquotes can be used as long as they are matched by an equal number in order to allow quoting text which itself has backquotes in it:Example 16: Backquote
Source: ⌨️
Output: 🖥️
Warning
To use the backquote markup with content containing backquotes which are adjacent to the start or end markup, you need to pad it with spaces. So when quoting a single backquote, it needs to be written as
@`` ` ``. This also means you cannot use backquote markup to specify a completely empty string. It must always contain at least one non-backquote character, e.g.,@` `. If you really need backquotes without whitespace padding, you can use a hook to intercept the backquote markup and strip it out.Attention
Note that when markup which has starting and ending delimiters appears alone on a line, the trailing newline will be rendered in the output. To avoid these extra newlines, use a trailing
@to turn it into whitespace markup which consumes that trailing newline, so e.g.@`...`followed by a newline becomes@`...`@followed by a newline. This is idiomatic for suppressing unwanted newlines. See here for more details.New in version 4.0: Backquote markup was introduced in EmPy version 4.0.